[과목 III] 데이터분석



- 각각의 정의
- 모집단을 추출해서 표본을 만들고, 표본의 통계량을 통해 모집단의 모수를 추론하게 된다.







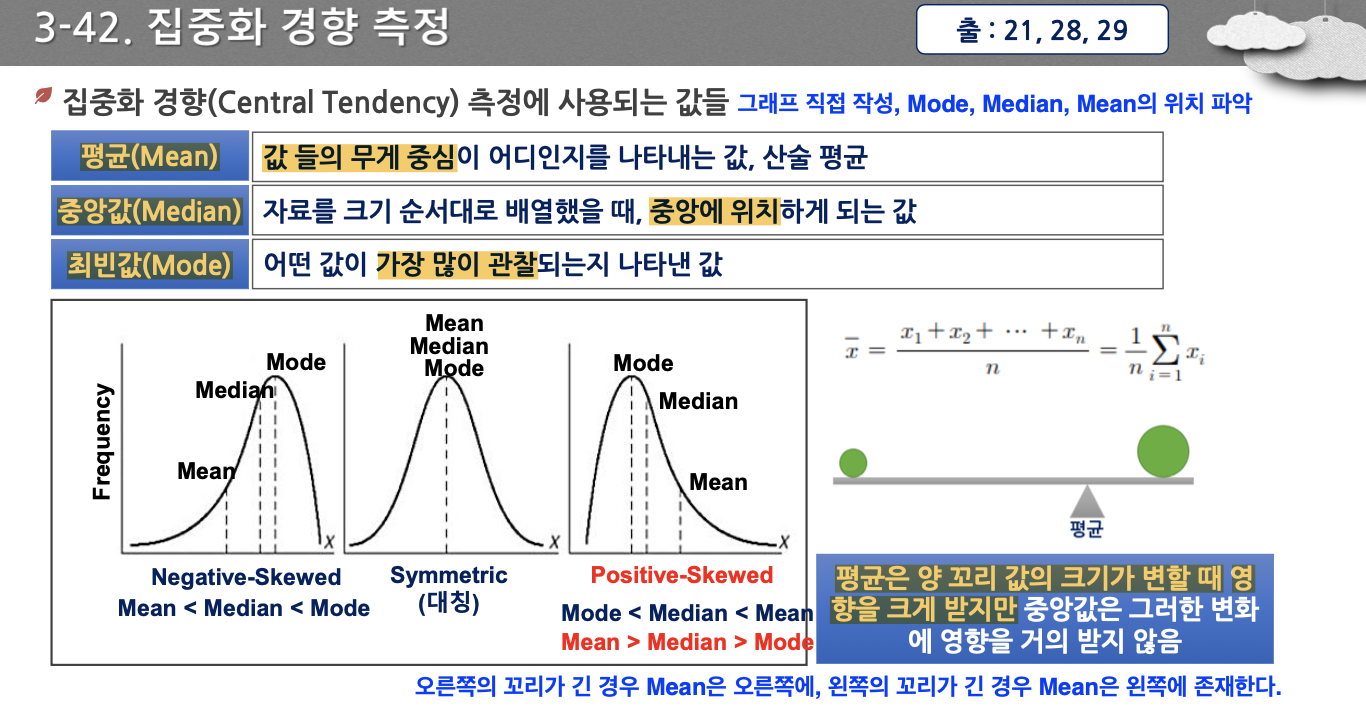
- 평균, 중앙값, 최빈값 직접 구하기
- 평균은 꼬리 값의 크기가 변할 때 영향을 받기 때문에, 꼬리 쪽에 가깝게 있다.
- 오른쪽으로 꼬리가 긴 경우 평균(Mean)은 오른쪽에 있고, 왼쪽으로 꼬리가 긴 경우 왼쪽에 Mean이 존재한다.
- 평균은 이상치에 영향을 많이 받지만, 중앙값은 이상치에 영향을 많이 받지 않는다.
- 편차의 개념 잘 알아두기
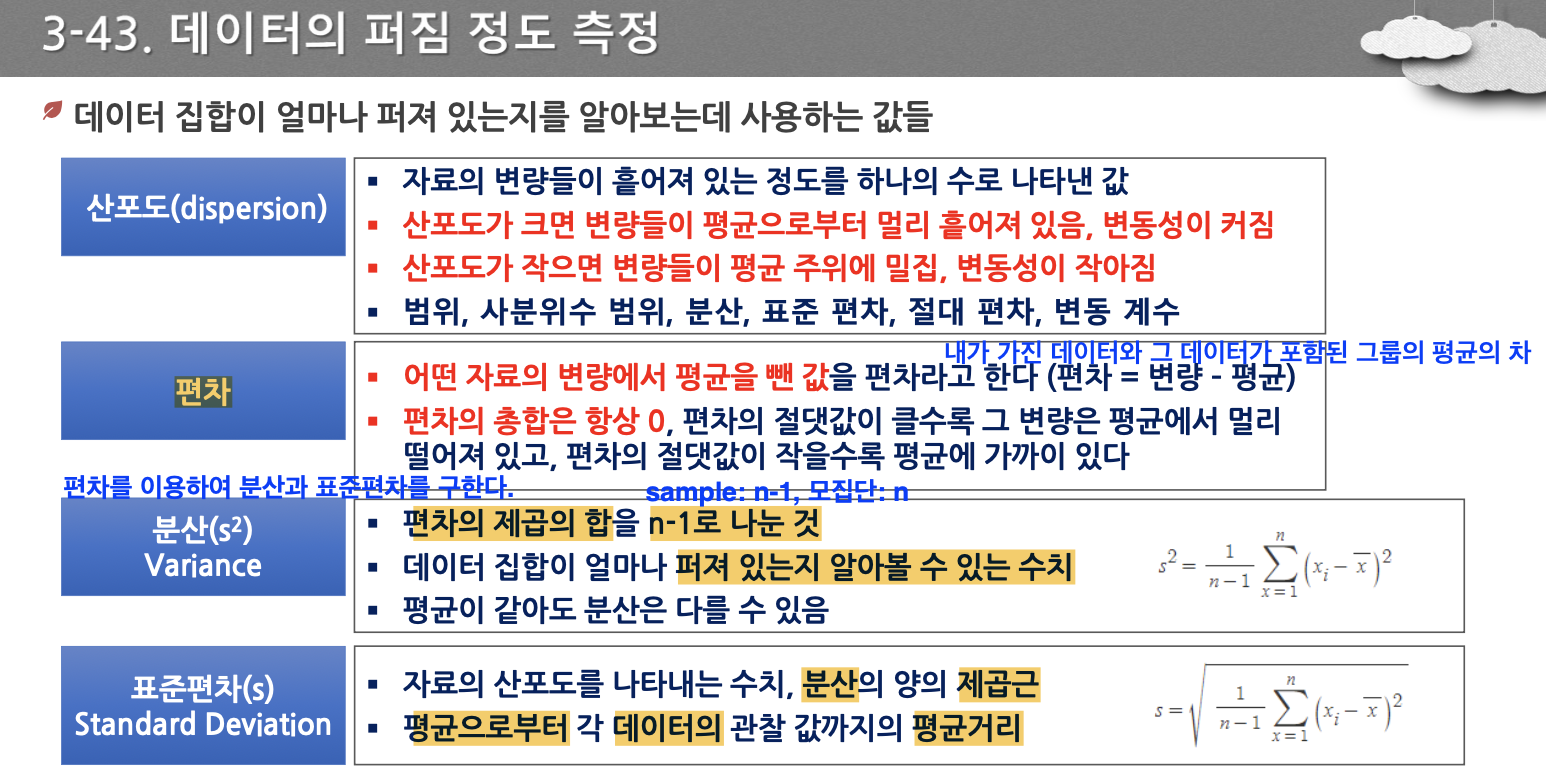
- 어떤 자료의 변량에서 평균을 뺀 값
- 내가 가진 데이터와 그 데이터가 포함된 그룹의 평균의 차이
- 편차를 이용해 분산과 표준편차를 구하게 된다.
- 분산과 표준편차의 공식 중요
- 분산: 데이터와 평균(엑스바는 X라는 집단의 평균을 나타내는 기호)의 거리인 편차의 제곱의 합을 데이터 갯수로 나누는 것
- 표준편차: 분산에 루트를 씌움
- 샘플에 대해서 이야기하는 것으로 n-1로 나눔, 모집단인 경우 n으로 나눈다.



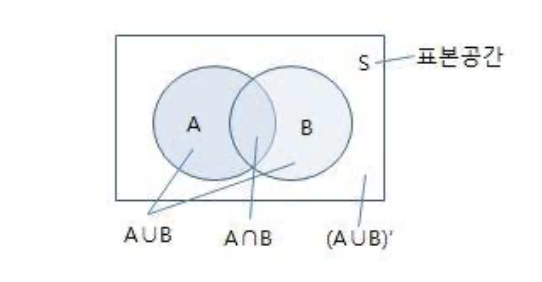
- 확률은 사건 나누기 표본공간이 된다. 확률값은 0~1의 값으로 나타난다.
확률은 0% 부터 100% 사이의 값을 가진다.어떤 사건 A 가 일어날 확률이 P(A)이면 그 사건이 일어나지 않을 확률은 1-P(A)이다.

- 독립사건
- P(B|A) = P(B), P(A∩B) = P(A)*P(B)
- 독립 - 확률을 바꾸지 않는 사건, 둘의 교집합은 두 확률의 곱
- 하나의 사건이 일어나느냐 마느냐와 상관없이 다른 사건이 일어날 확률이 변하지 않으면, 두 사건의 관계가 독립(independent)이라고 한다. 그렇지 않은 경우 두 사건의 관계가 종속(dependent)이라고 한다.
- 복원추출일 경우에는 매번의 추출이 독립이고, 비복원추출일 경우에는 종속이다.
- 두 사건이 서로 독립일 때, 두 사건이 모두(함께, and) 일어날 확률은 각각의 비조건부 확률을 곱하여 얻는다. 이를 좁은 의미의 곱셈법칙이라고 부른다.
- 두 사건 A와 B가 독립이면, P (A and B) = P(A)P(B)
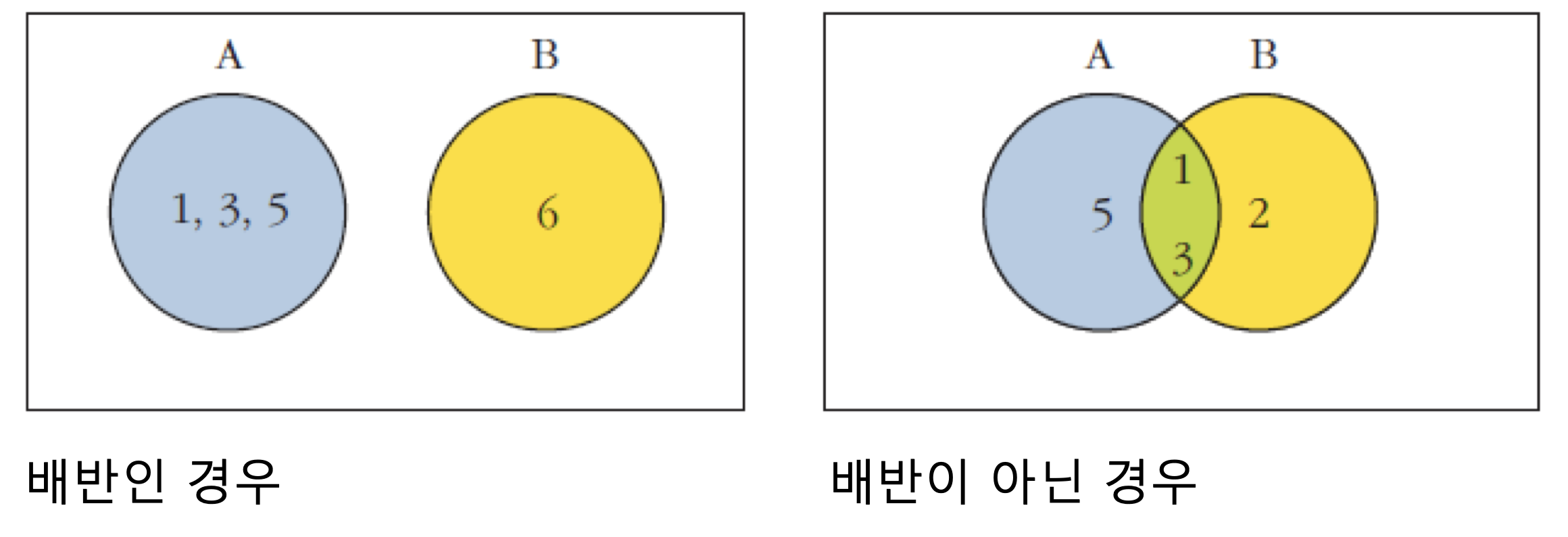
- 배반사건
- P(A∩B)이 없으므로, 각각의 확률의 합이 합집합된다.
한 사건이 발생할 때 다른 사건이 함께 발생할 수 없는 경우 두 사건은 ‘상호배반(mutually exclusive)’ 또는 단순히 ‘배반’ 관계에 있다고 한다.
- 종속사건
- 다른 사건에 영향을 주는 사건
- P(A∩B) = P(A|B) *P(B)
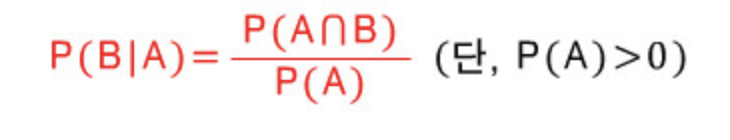
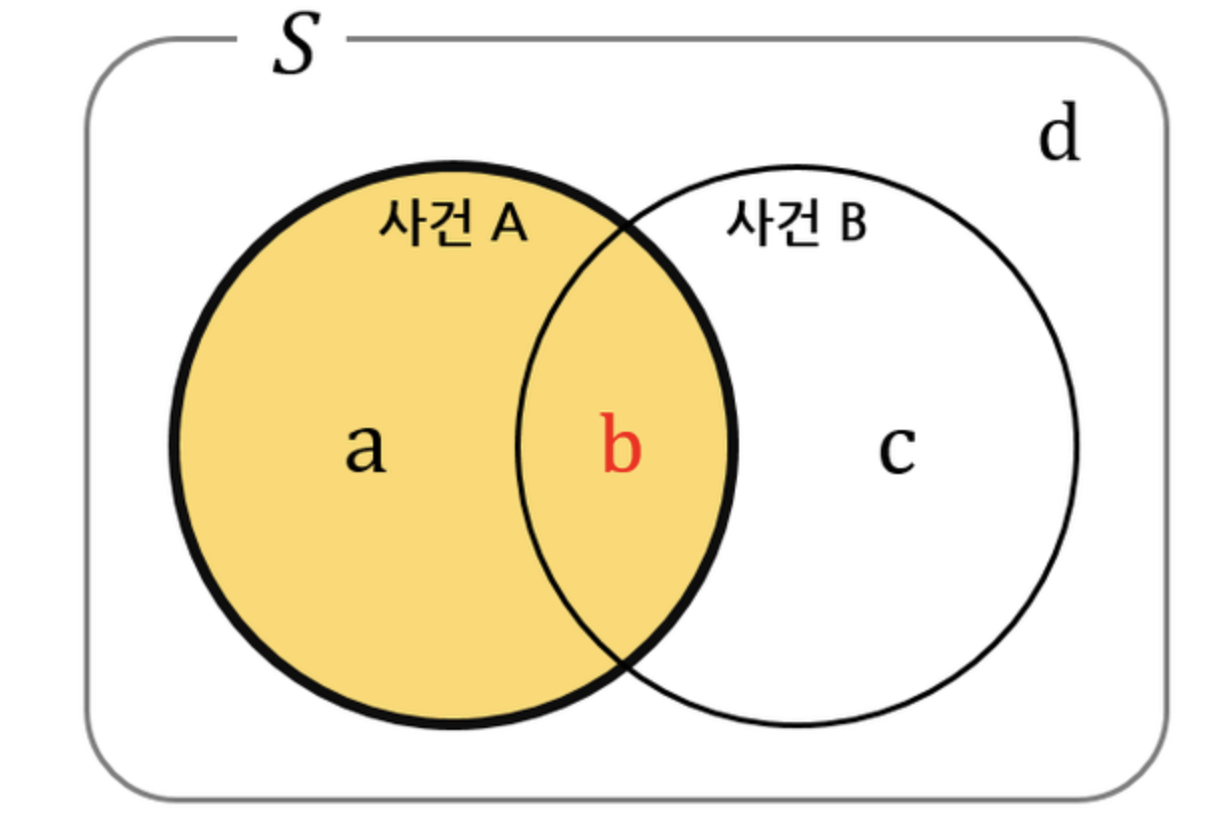
- P(A and B): 결합확률 (joint probability)
- 두 사건이 함께 일어날 확률
- 두 사건이 모두 일어날 확률은 ‘하나의 사건이 일어날 확률’과 ‘하나의 사건이 일어났다는 조건 하에서 다른 하나의 사건이 일어날 조건부확률’을 곱하여 얻는다.
- P(A and B) =P(A)·P(B|A) =P(B)·P(A|B)
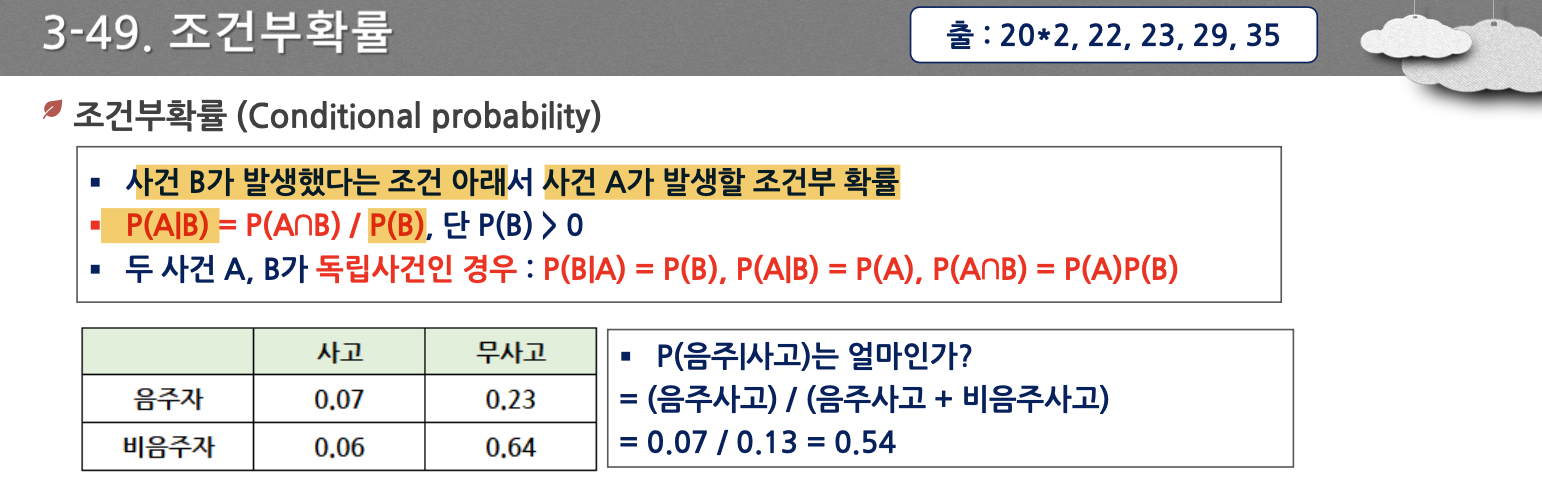
- P(A | B): 조건부확률 (conditional probability)
- 사건 A가 주어진 조건 하에서 사건 B가 일어날 확률
- P(A), P(B): 주변확률 (marginal probability)
- 비조건부 확률

- P(B)가 분모로 가고(base), 둘의 교집합의 확률이 분자로 간다.
- 종속사건은 조건이 분모로, 독립사건은 둘의 곱

- 각각의 확률을 구한 후 더함

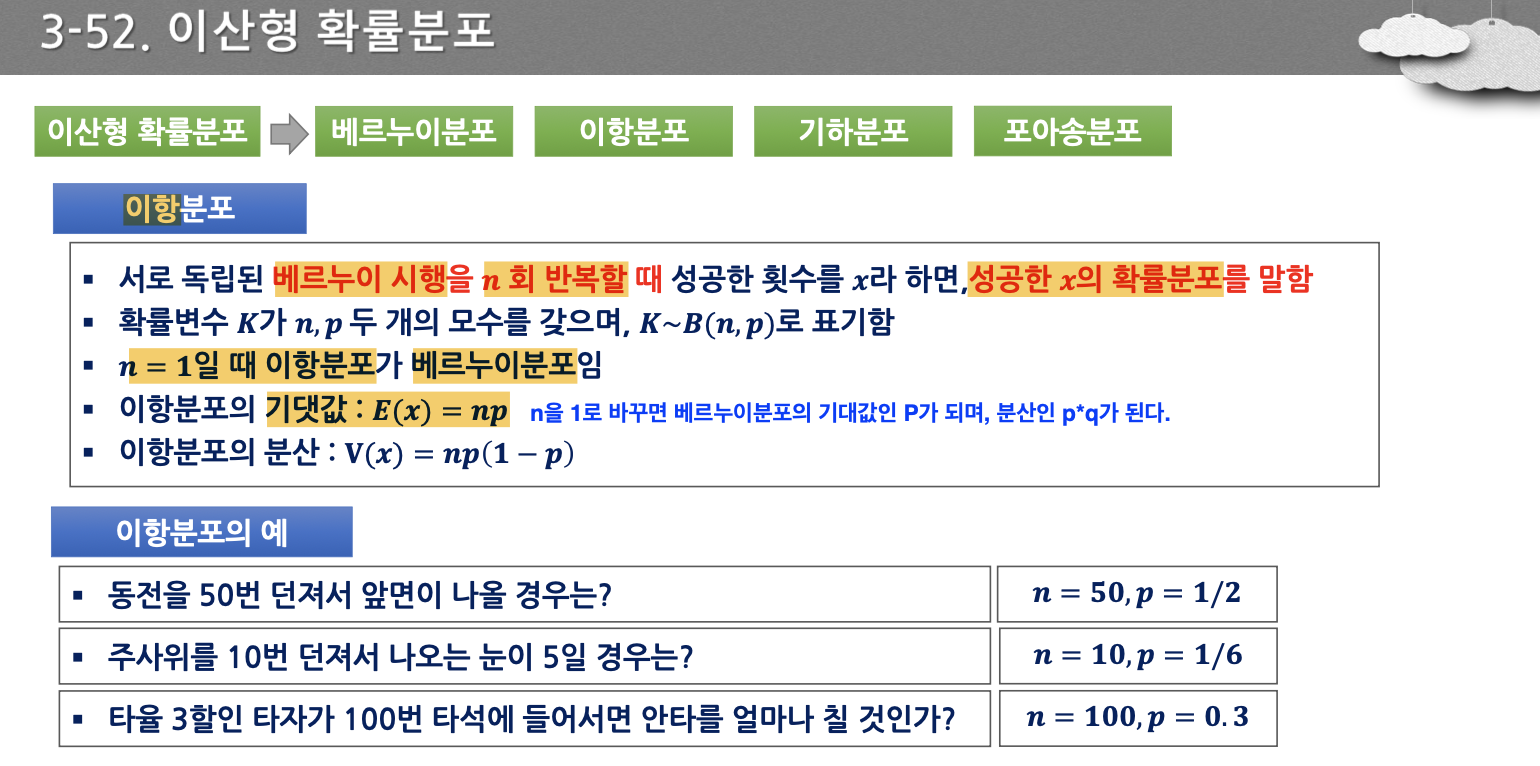
- 숫자가 이산적이다 → 이산형 확률분포
- 이산형 확률 분포와 연속형 확률 분포의 구분
- 연속형 확률분포는 구간에 관한 확률을 표시할 수 있다.
- x=0일 때의 확률을 p, x=1일 때의 확률을 q라고 했을 때, p가 0~1 사이의 값일 때, q는 1-p가 성립한다면 베르누이분포다.
- 모수가 p 하나이며, 서로 반복되는 사건이 일어난다.
- p는 기댓값, 분산은 p와 q의 곱이다.
- 모수
- 모집단의 특성을 나타내는 수치들
- 모집단의 평균(μ), 분산(σ^2) 같은 수치들을 모수(parameter)라고 함

- n=1로 바꾸면, 베르누이 분포의 기대값인 p가 되며, 분산인 p와 q가 되는 것이다.
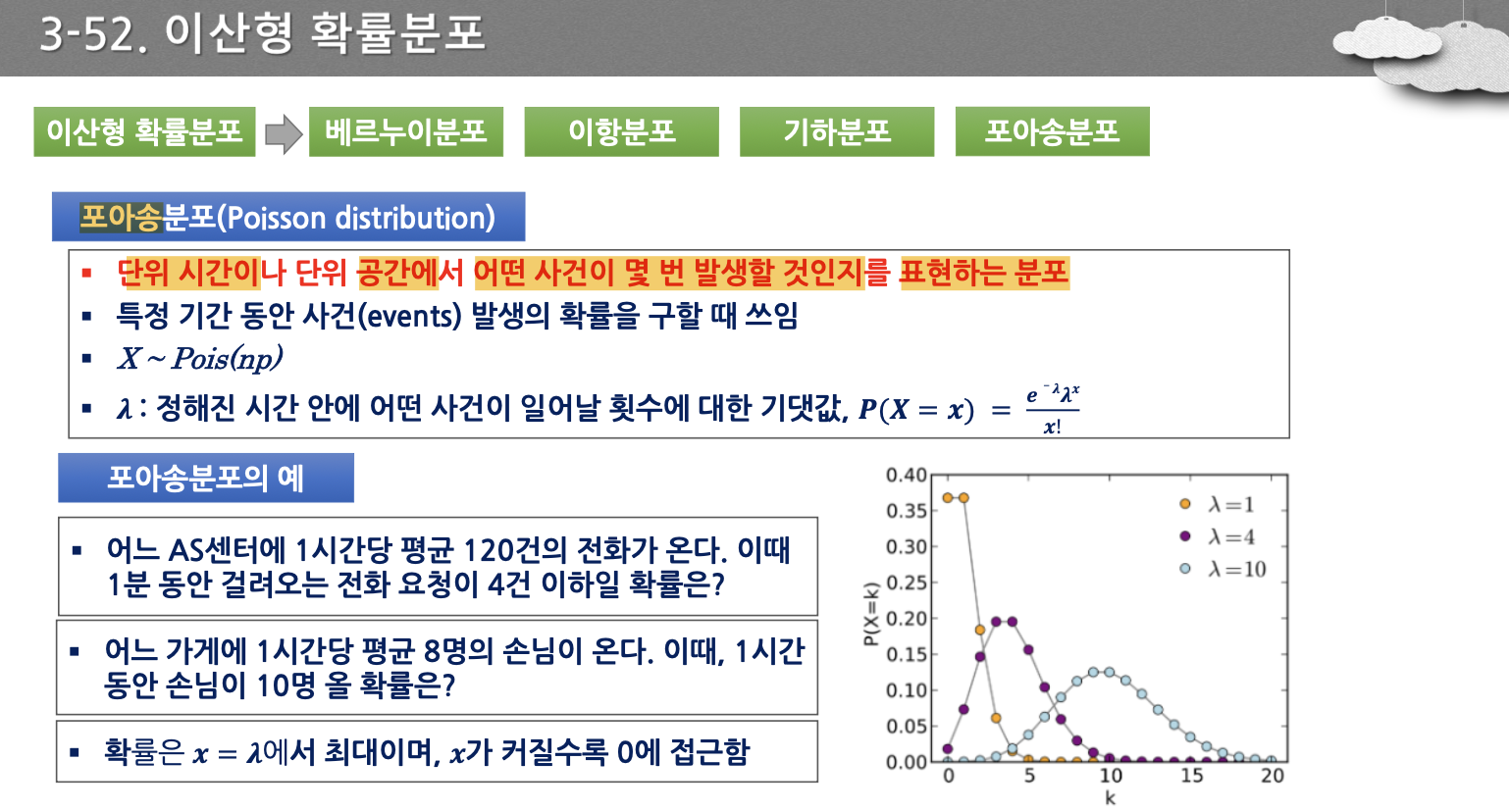
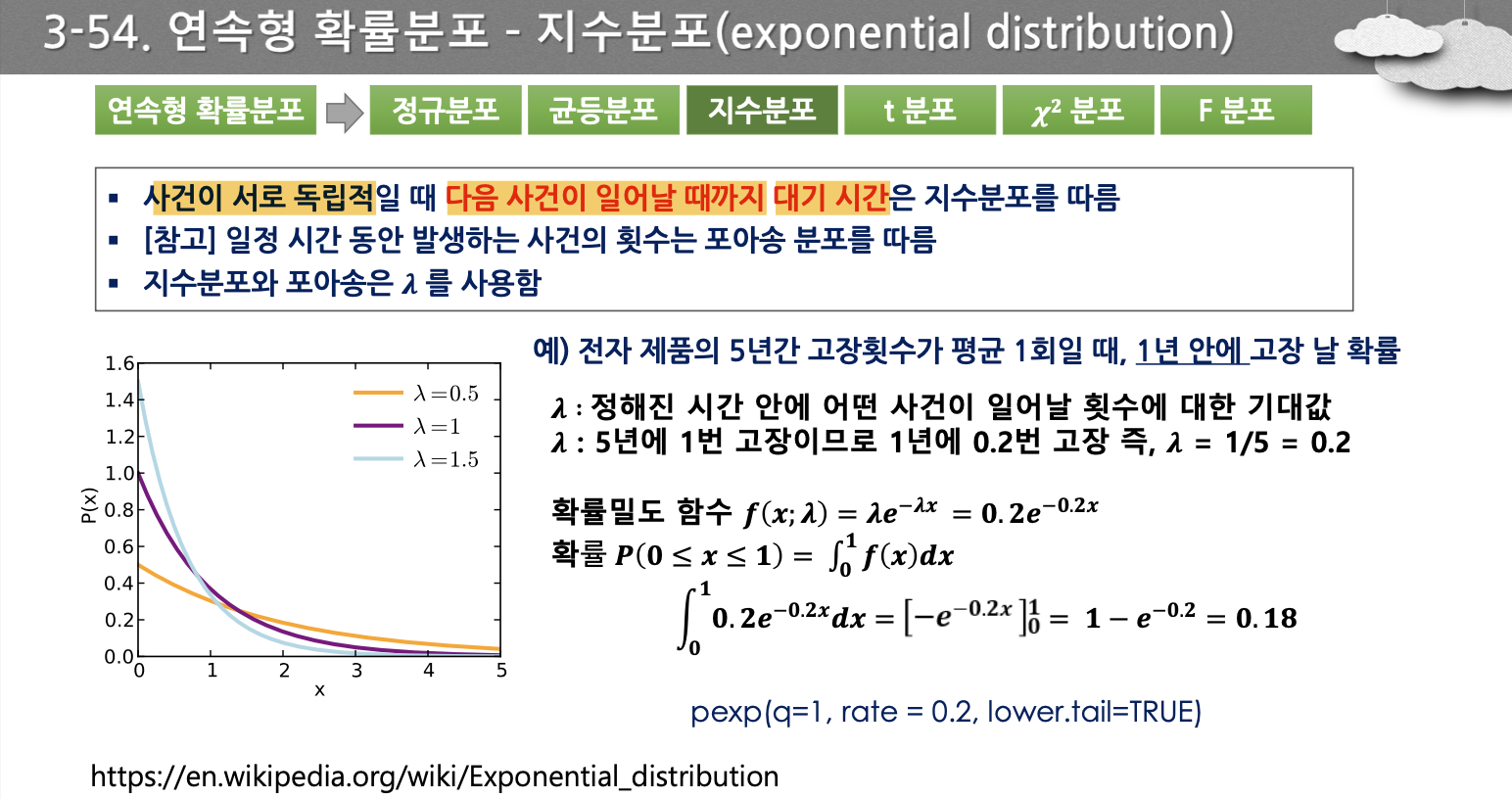
- 포아송 분포의 정의. 구하는 방법x


- 기댓값 식: 시그마, 인테그랄
- 식 보기
- 표준 정규 분포, z 분포
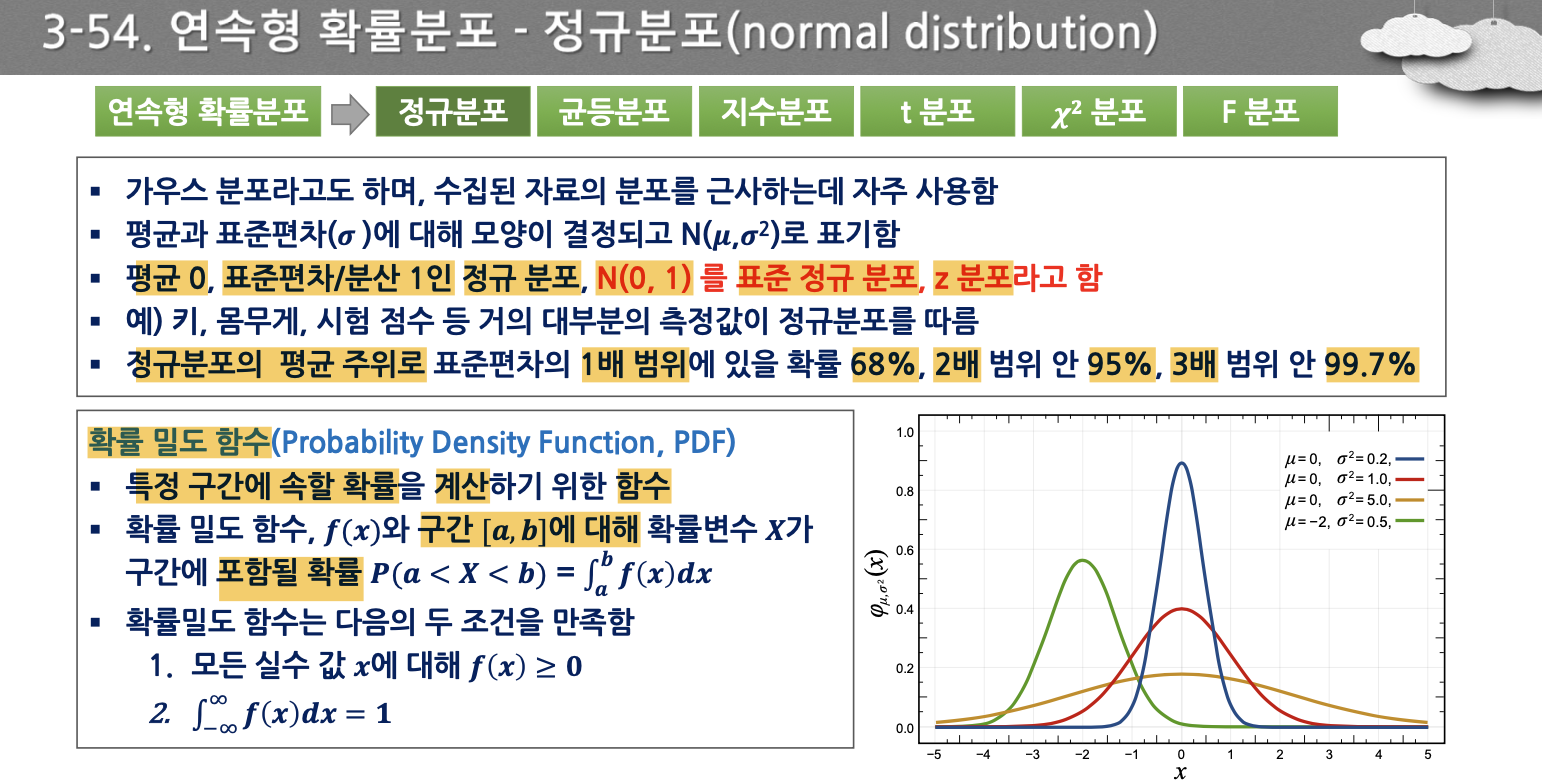
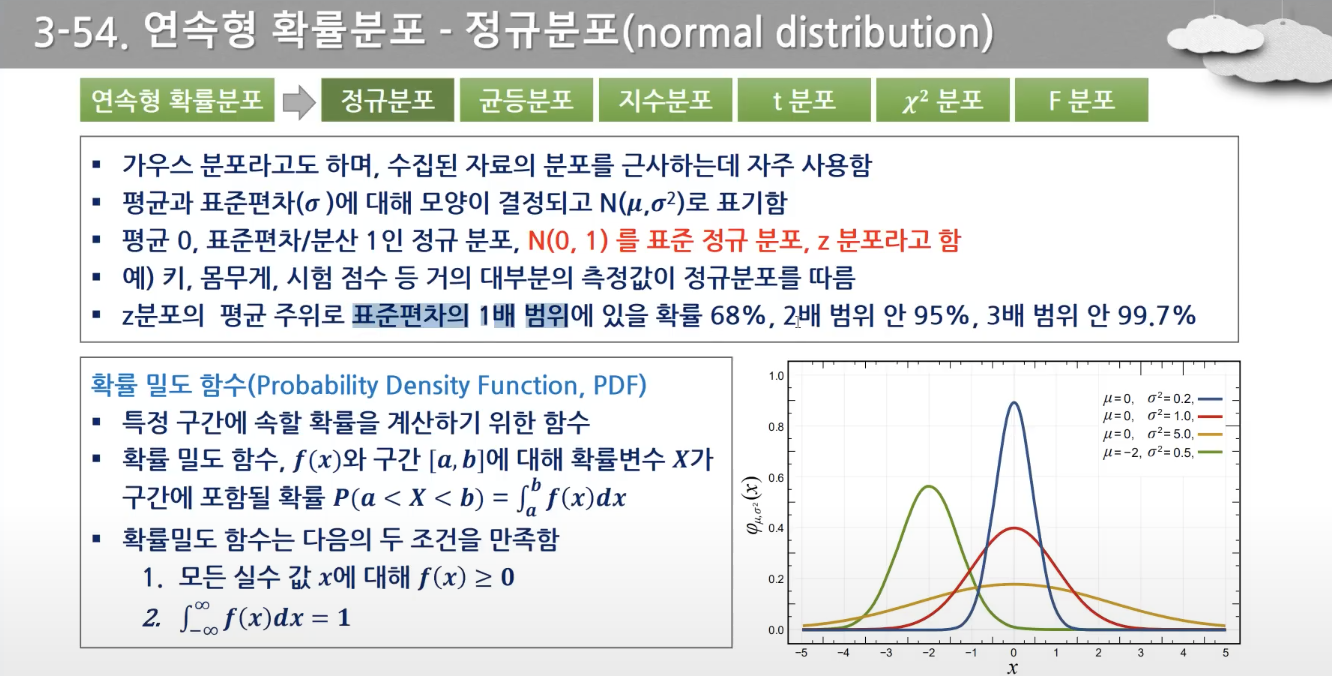
- 평균 0, 표준편차/분산 1인 정규분포
- N(0,1)를 표준 정규분포라 함
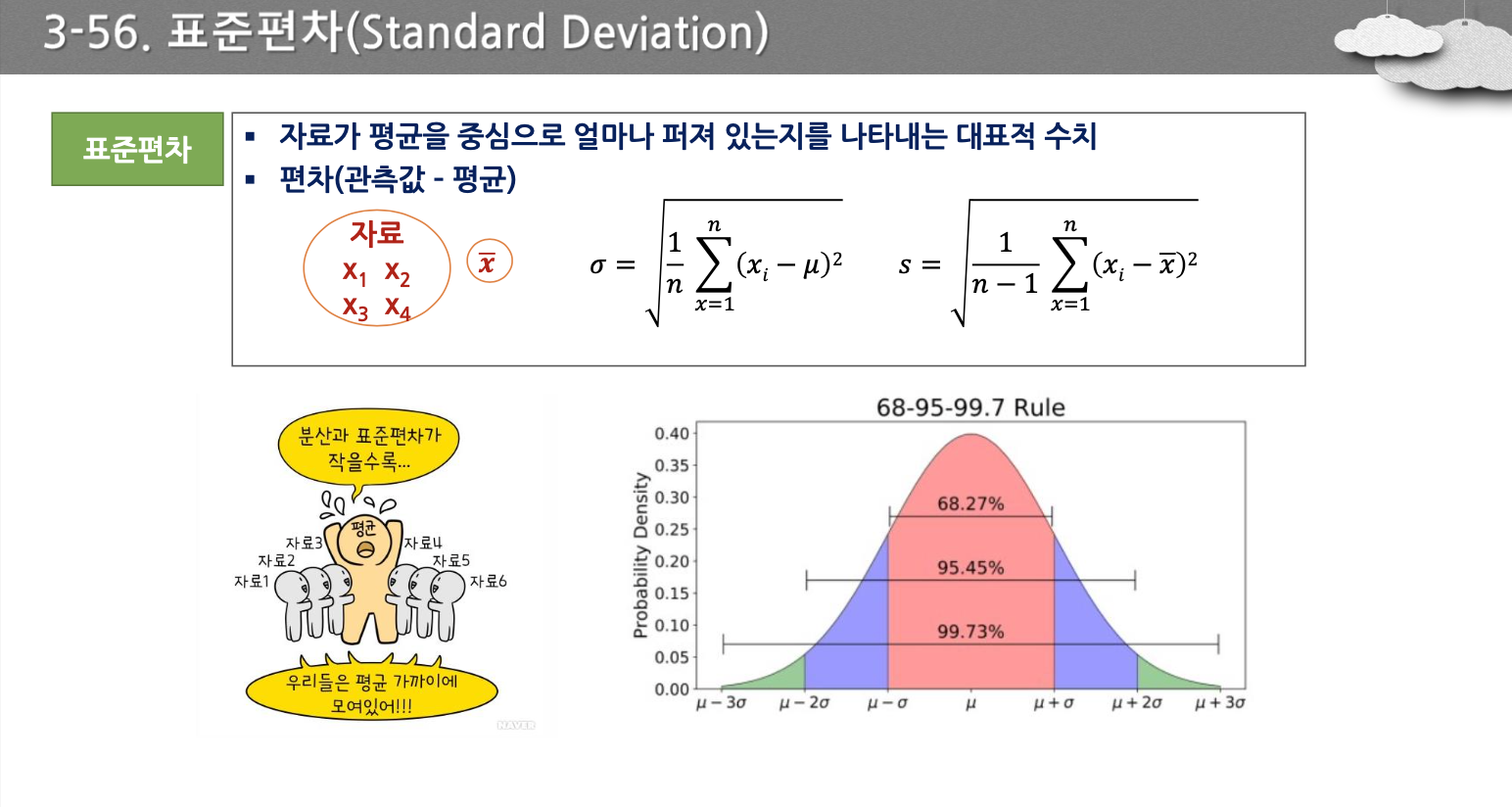
- 표준편차(S) Standard Deviation
- 자료의 산포도를 나타내는 수치, 분산의 양의 제곱근
- 평균으로부터 각 데이터의 관찰 값까지의 평균거리
- % 수치 간단하게 알고 있기
- 연속형 확률분포의 확률 밀도 함수는 특정 구간에 속할 확률을 계산하기 위한 함수다.
- 무수히 많은 숫자로 이루어져 있기 때문에, 특정 숫자를 말할 수 없다. → a~b까지 라는 구간에 대해 구하게 된다.

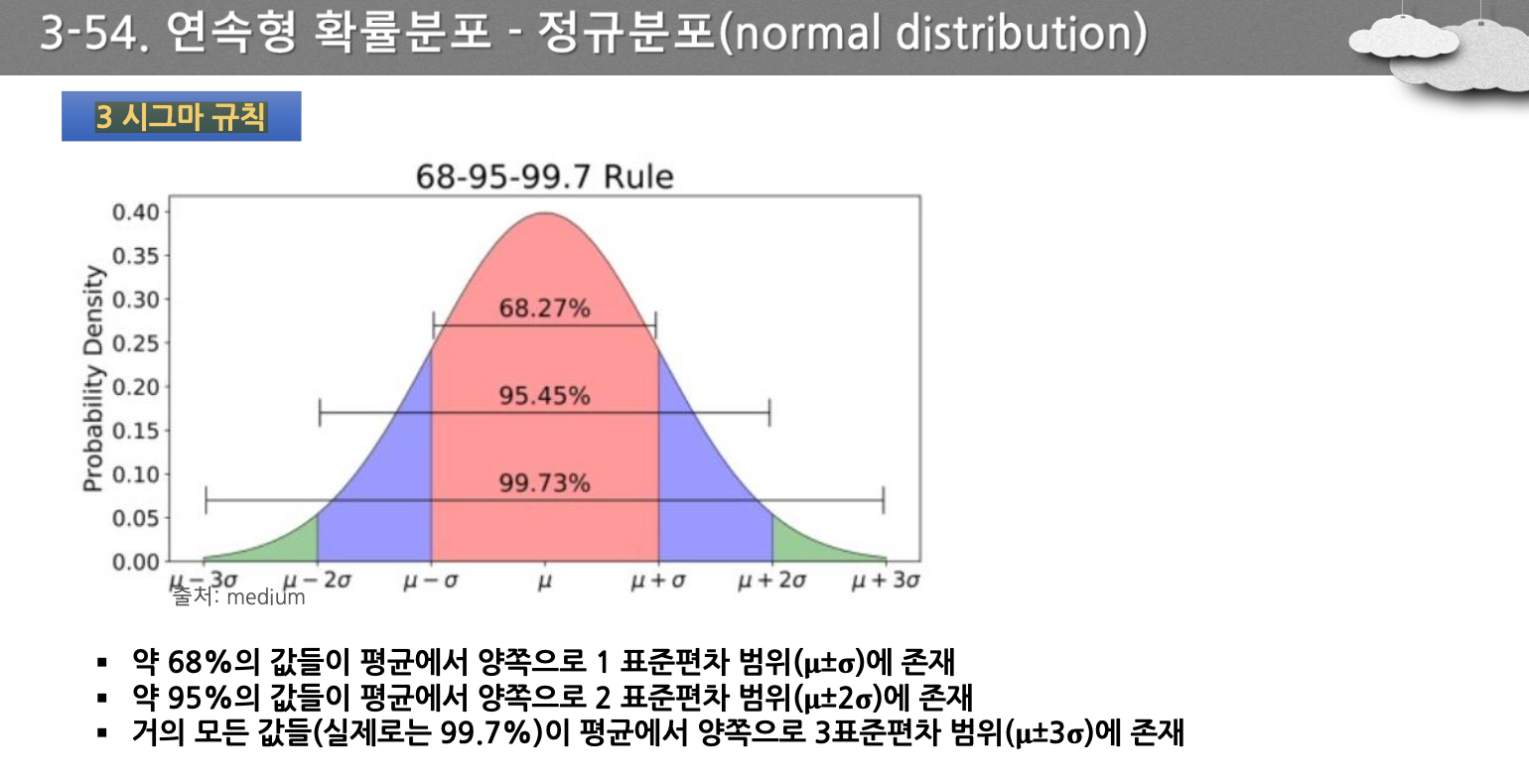
- 평균을 기준으로, 1시그마, 2시그마, 3시그마
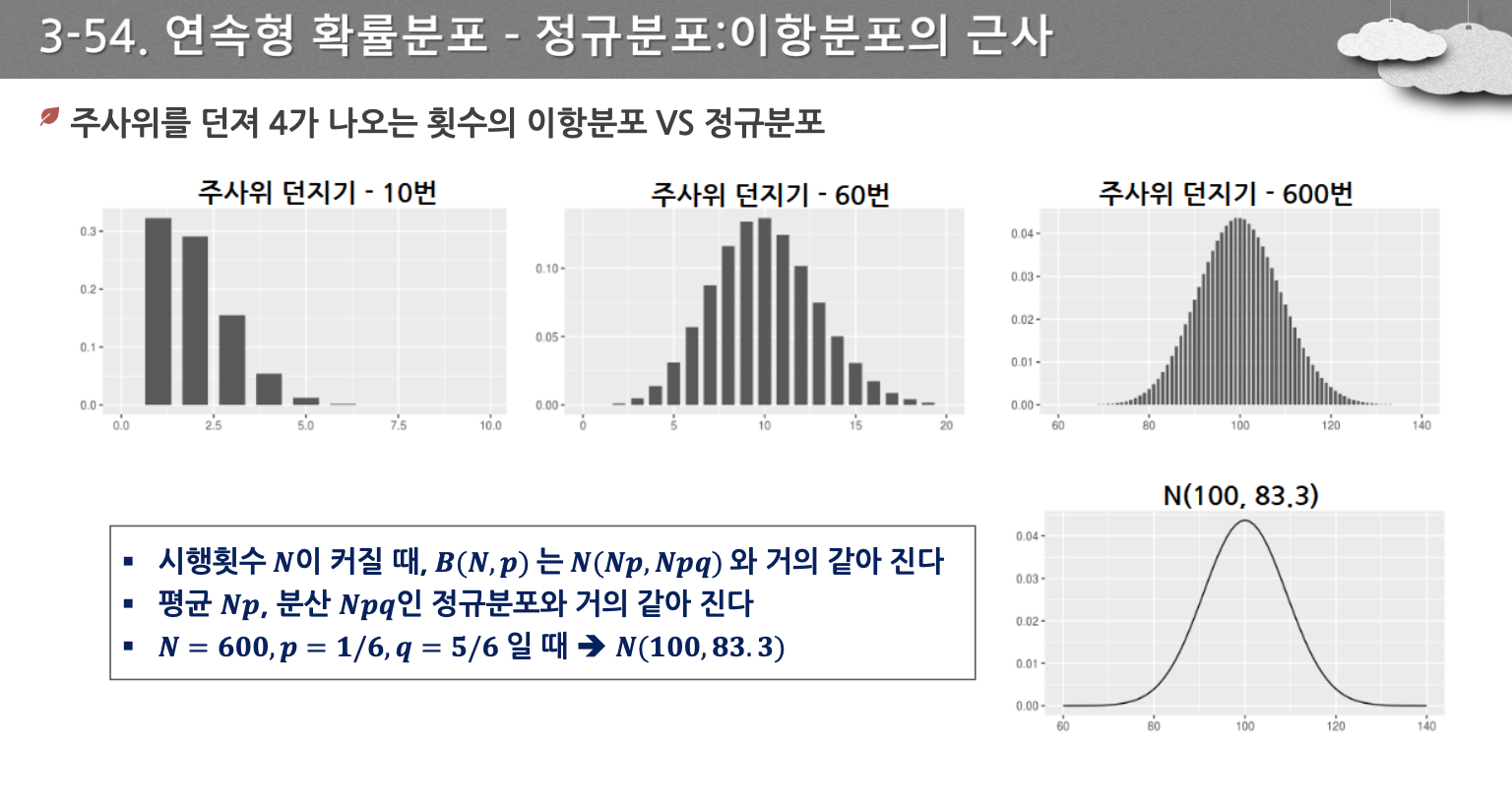
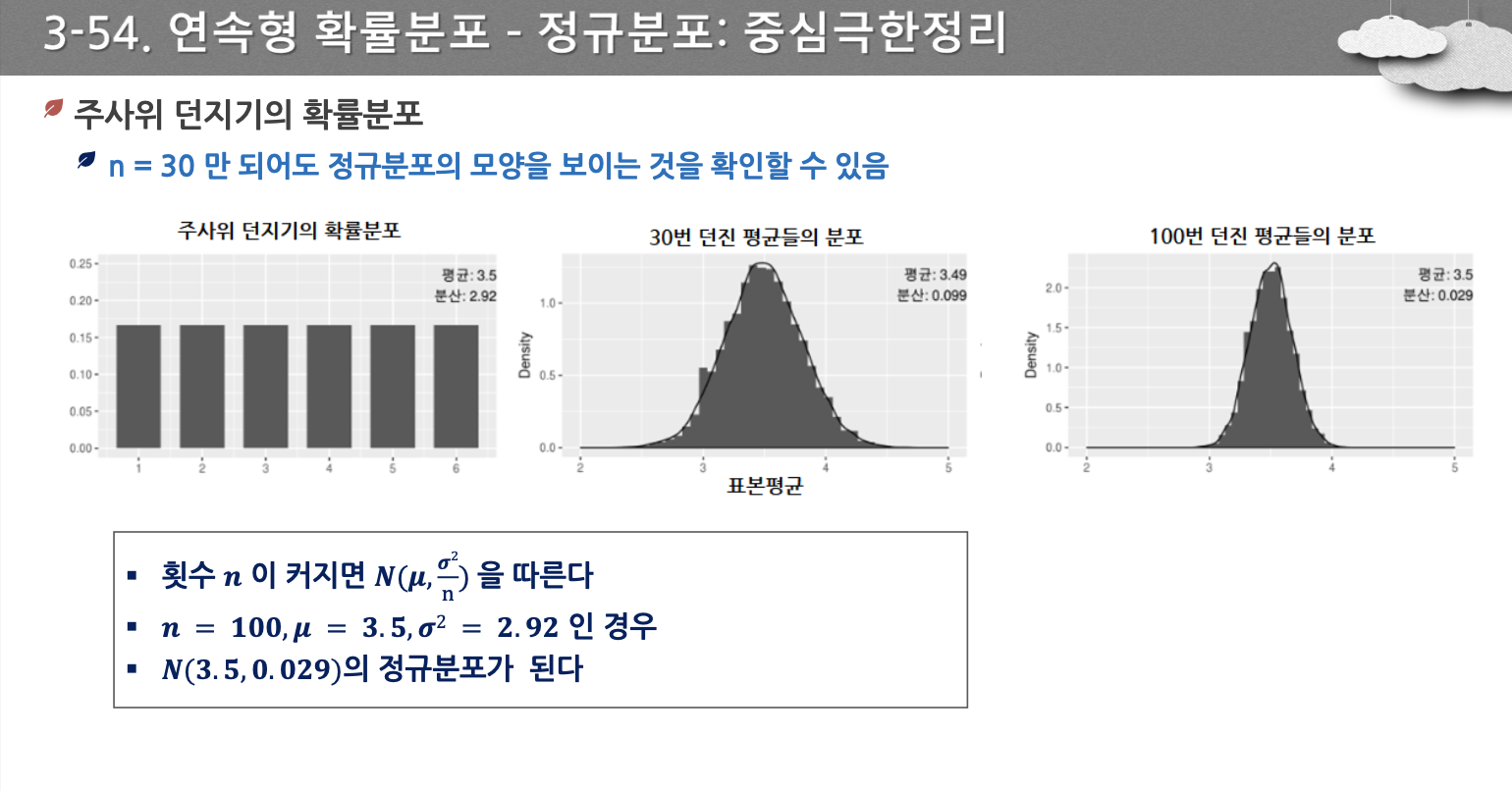
- 모집단의 푼포와 상관없이 표본의 크기가 30이상이 되면 N이 커짐에 따라 표본평균의 분포가 정규분포에 근사해 짐
- 이항 분포, 포아송 분포, t-분포, 지수 분포, 기하 분포도 n이 커지면 정규분포로 연결된다.
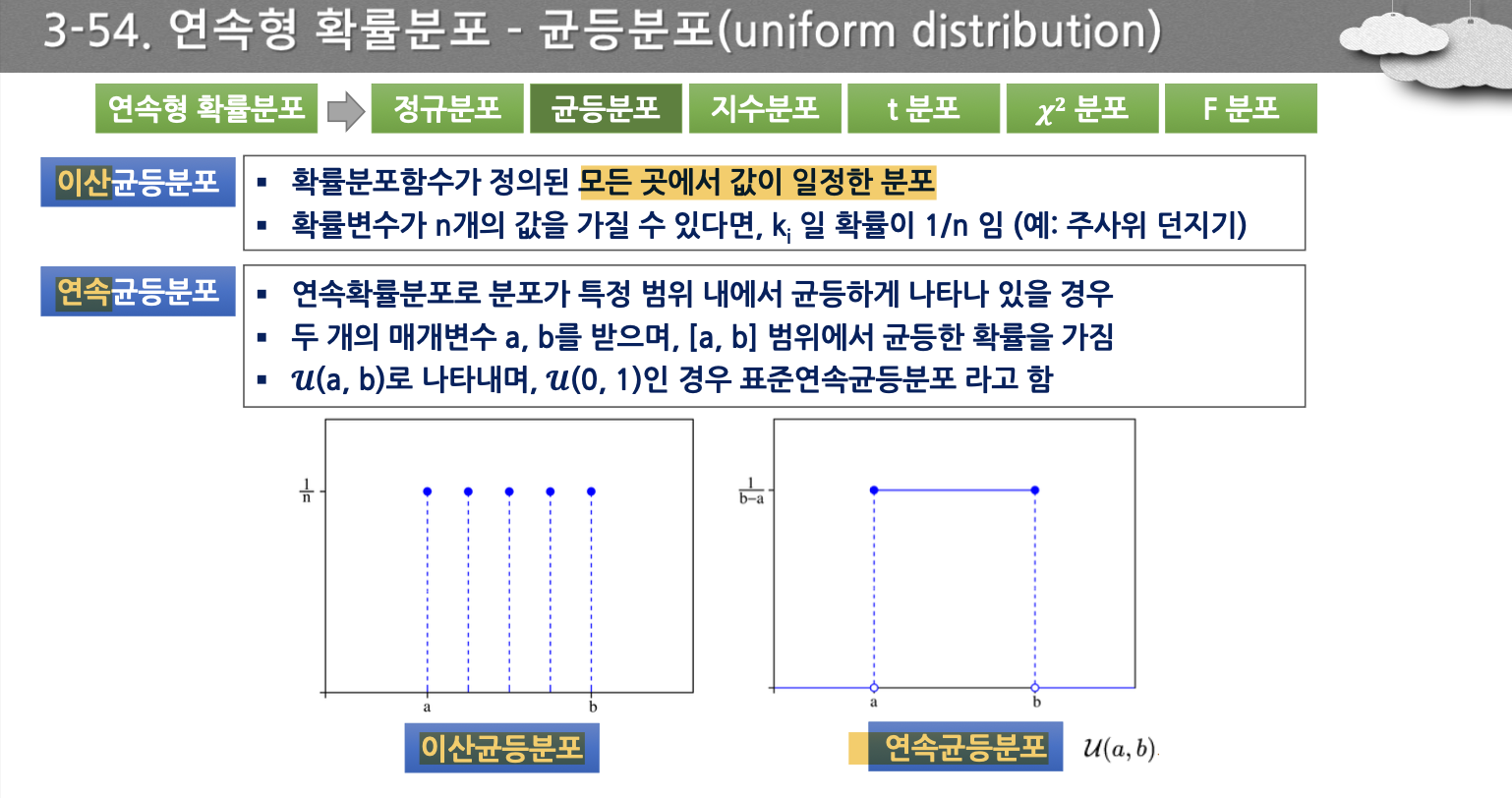
- 균등보포는 이산균등분포와 연속균등분포가 있다.
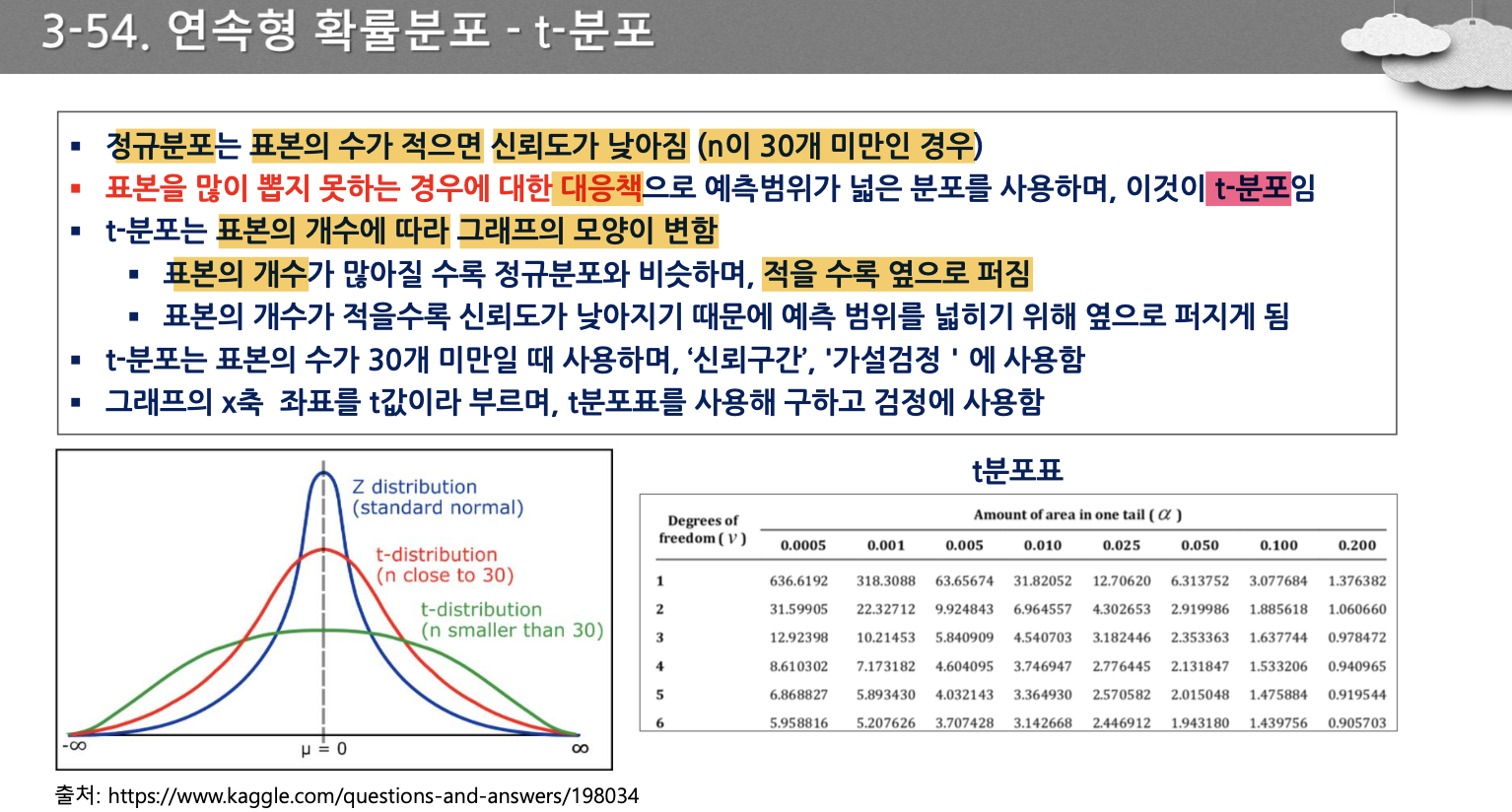

- z분포, t분포(30 근처, 30보다 작은 경우)

- 카이제곱은 분산이라는 단어와 같이 연결해두기
- 자유도가 높아졌을 때(df = 10), 정규분포와 비슷하게 올라갔다 내려옴
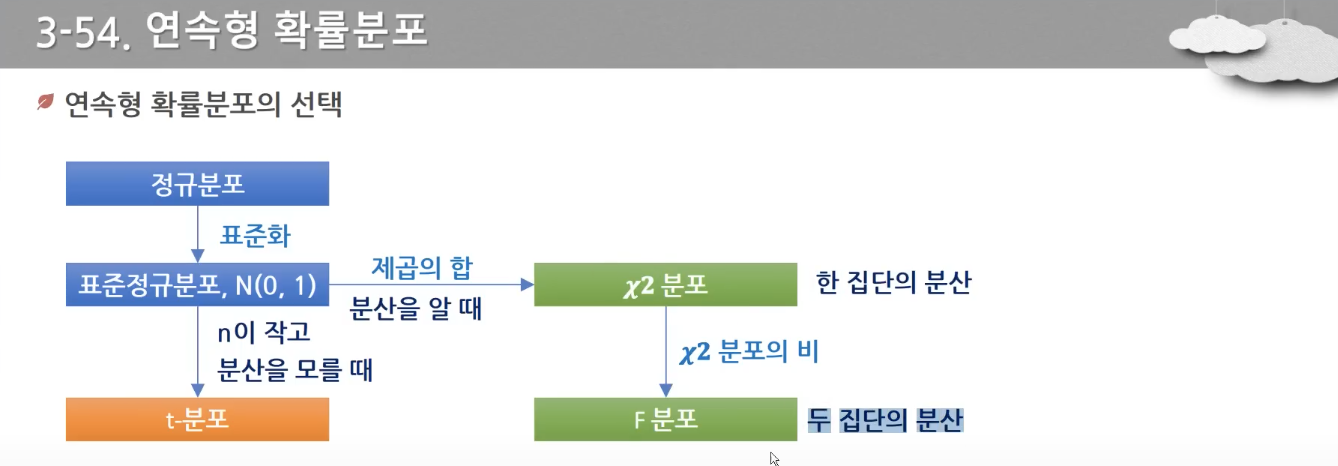

- 정규분포에서 표준화(평균이 0, 표준편차, 분산이 1)를 하면 표준정규분포가 된다.
- n이 작고 분산을 모를 때 t분포를 이용한다.
- 분산을 알 때 한 집단의 분산이라면 카이제곱 분포, 두 집단의 분산이라면 F분포를 이용한다.

- 모수적 추론과 비모수적 추론 구분, 종류


- 평균값 계산에 사용한 데이터 갯수에 루트 씌워서 분모로 들어가고, 원시데이터의 표준편차가 분자가 된다.
- 모집단에 대해서, n의 갯수가 크다면 표본에 대해서도 표본오차를 구할 수 있다.
- n이 클수록 작은 값이 나온다. 데이터의 갯수가 많으면 좋다.(표준오차가 줄어들기 때문)
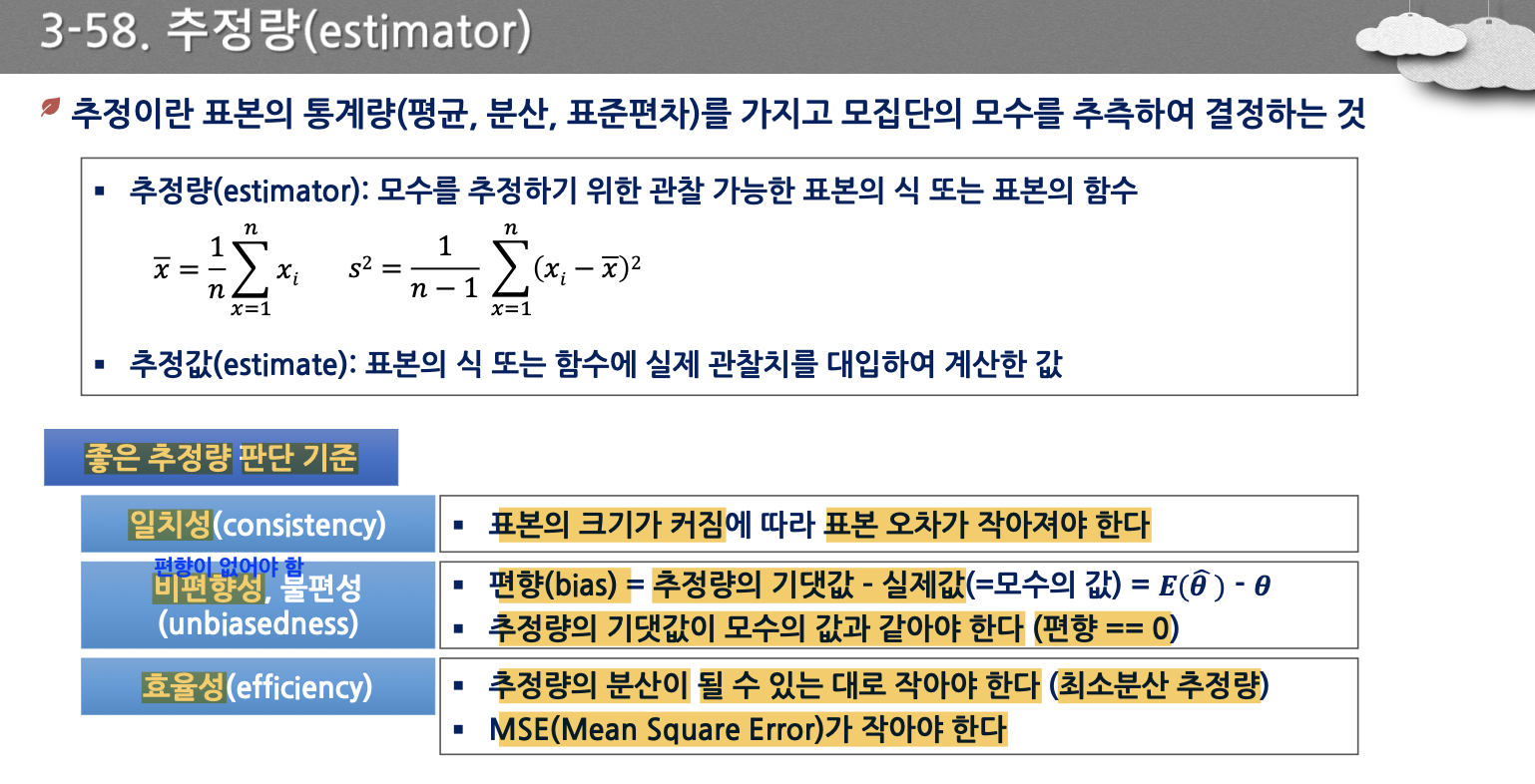
- 표준정규분포 → z, t-분포 → t
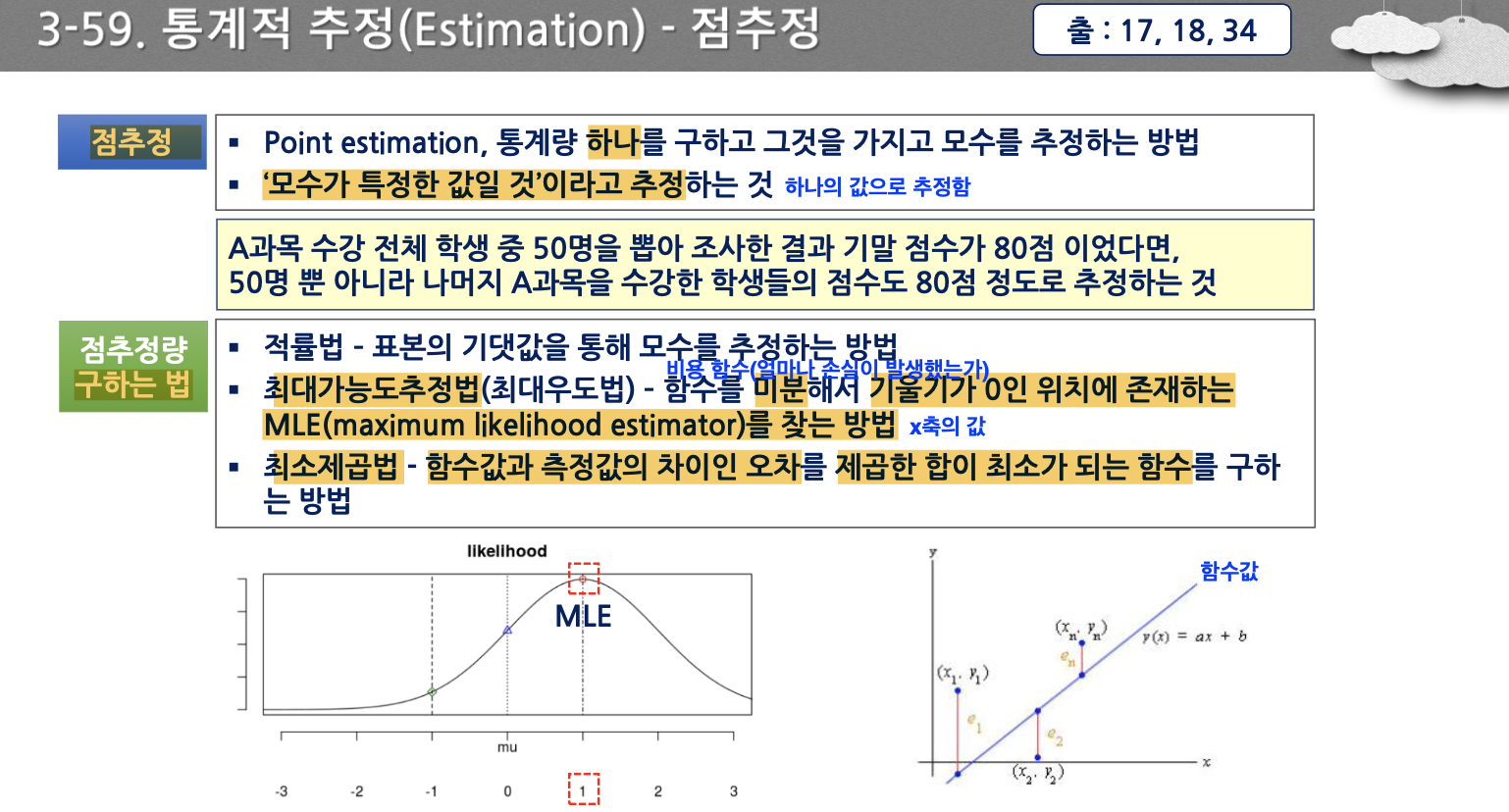
- 최대가능도추정법, 최소제곱법
- 함수는 비용함수로 얼마나 손실이 났는가에 관한 함수로 기울기가 0인 지점에서 손실이 최소임을 나타낸다. 그때의 x축의 값을 점추정이라고 한다.
- 예측하는 값을 가진 함수값과 실제 값의 차이인 오차를 제곱한 합이 최소가 되는 함수를 찾는 것이 최소제곱법이다.
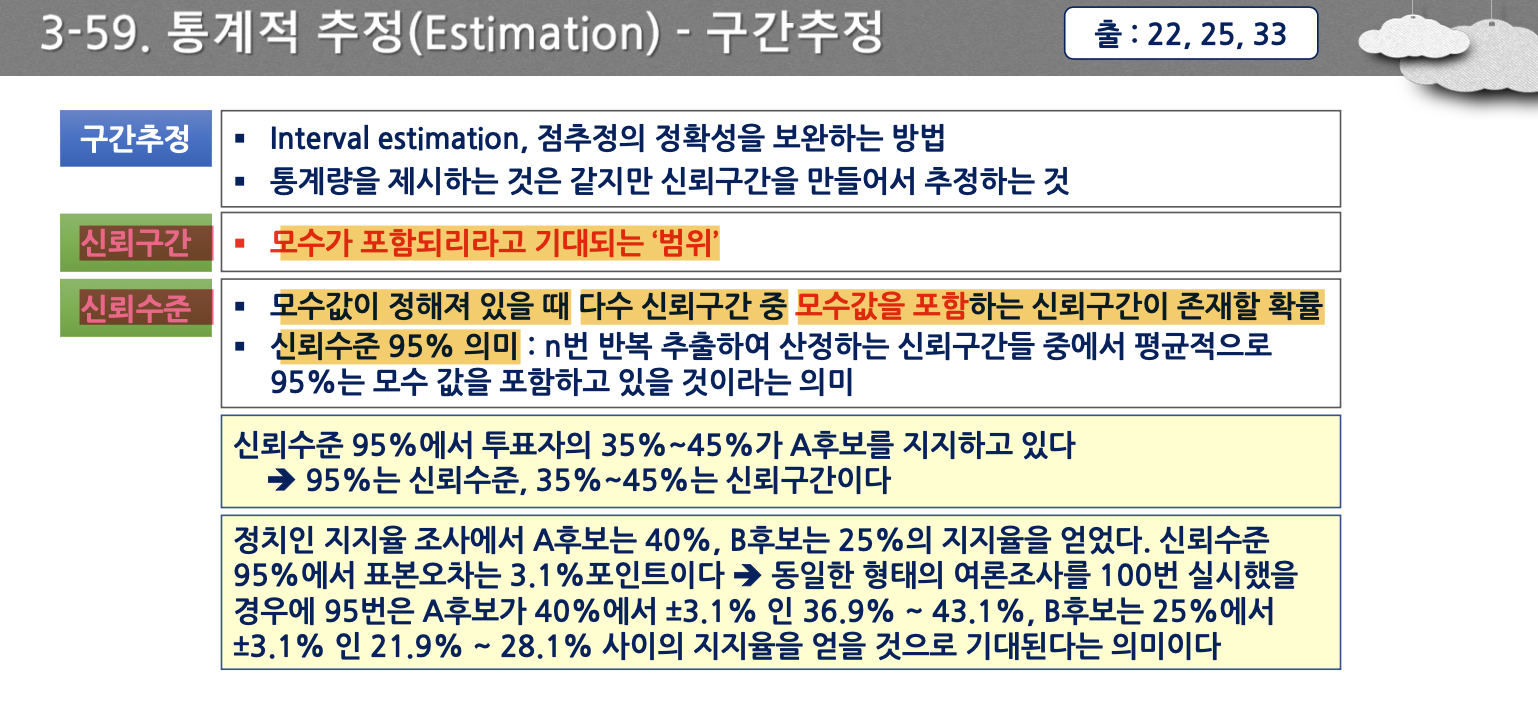
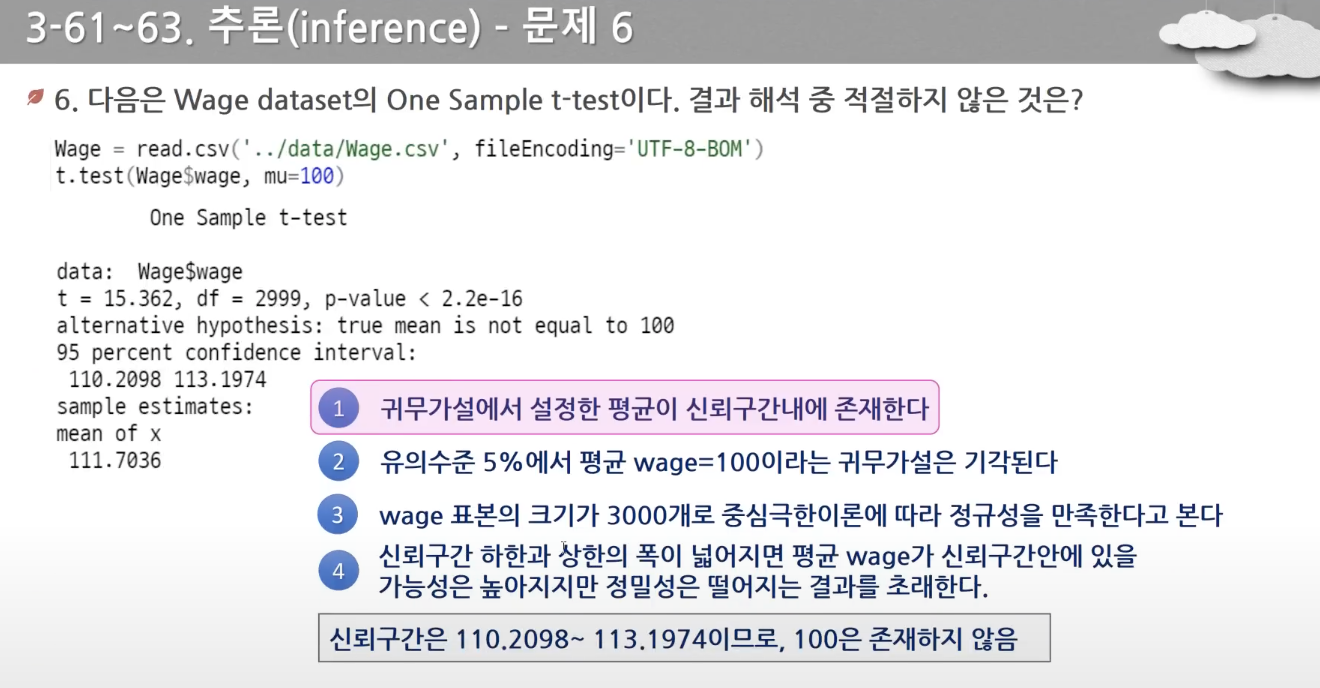
- 신뢰구간과 신뢰수준의 관계 알아두기
- 신뢰구간은 모수가 포함되리라고 기대하는 범위이며, 신뢰수준은 모수값이 정해져 있을 때 다수 신뢰구간 중 모수값을 포함하는 신뢰구간이 존재할 확률이다.
- 신뢰수준 95%의 의미
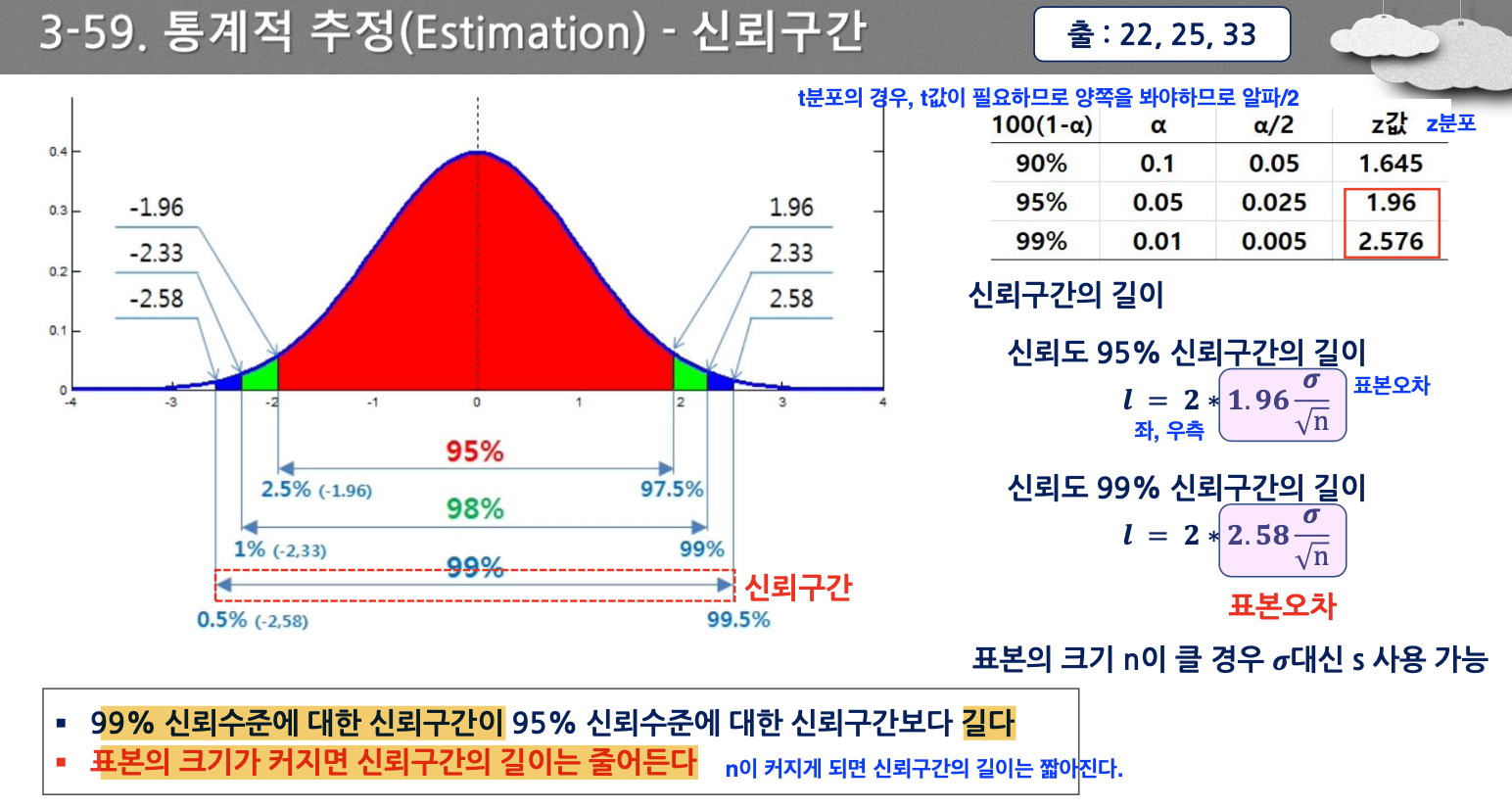
- 신뢰수준에 대한 신뢰구간
- 신뢰도가 높아졌을 때 신뢰구간도 길어진 것을 볼 수 있다.
- 99% 신뢰수준에 대한 신뢰구간이 95% 신뢰수준에 대한 신뢰구간보다 길다.
- 신뢰구간이 길 때 신뢰수준이 높아지는 것
- 표본오차에서 n이 커질 때, 신뢰구간의 길이는 짧아질 것 → 표본의 크기가 커지면 신뢰구간의 길이는 줄어든다.
- t분포의 경우 t 값을 구해야 하며, t에 대해서 95% 신뢰수준에 대한 신뢰구가을 구할 경우, 알파 값을 양쪽을 보고 α/2인 0.025를 적용해야 한다.
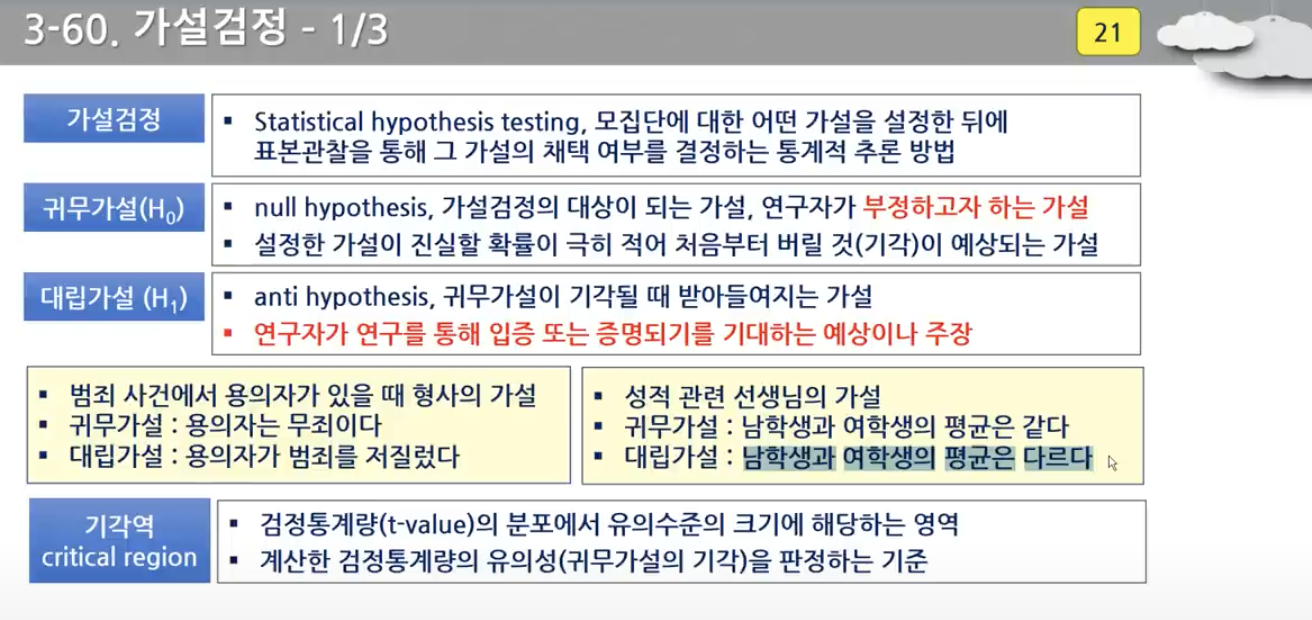
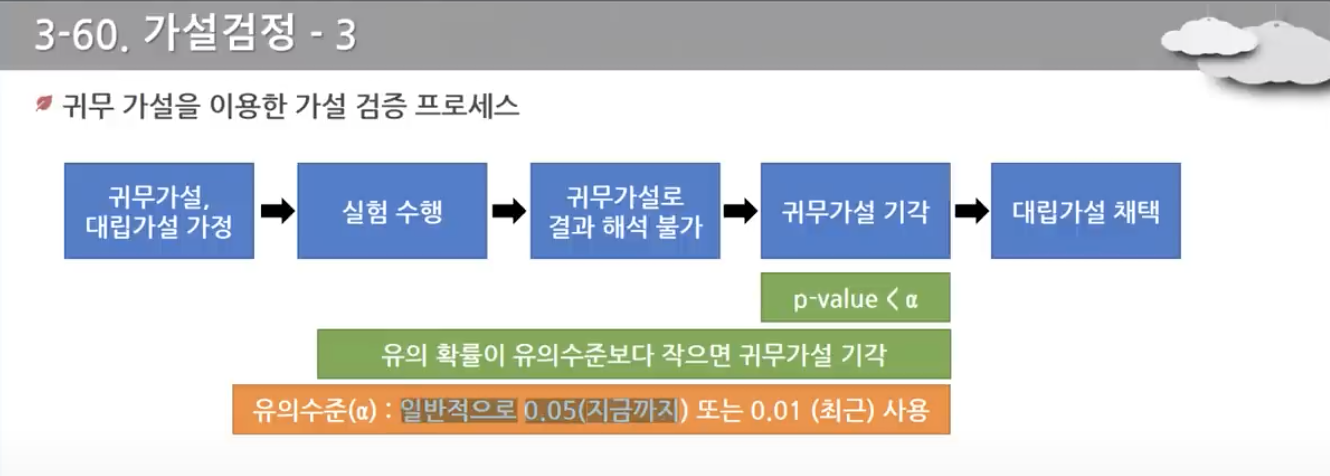
- 귀무가설과 대립가설 잘 알아두기
- 귀무가설은 연구자가 부정하고자 하는 가설
- 일반적으로 같다, 변화가 없다와 같은 것들이 귀무가설이 된다.
- 대립가설은 귀무가설이 기각될 때 받아들여지는 가설
- 연구자가 연구를 통해 입증 또는 증명되기를 기대하는 예상이나 주장이다.
- 다르다와 같은 것들이 대립가설이 된다.
- 귀무가설은 연구자가 부정하고자 하는 가설


- 1종 오류는 허용치를 두고, 2종 오류는 가장 작게 해주는 검정 방법을 사용한다.
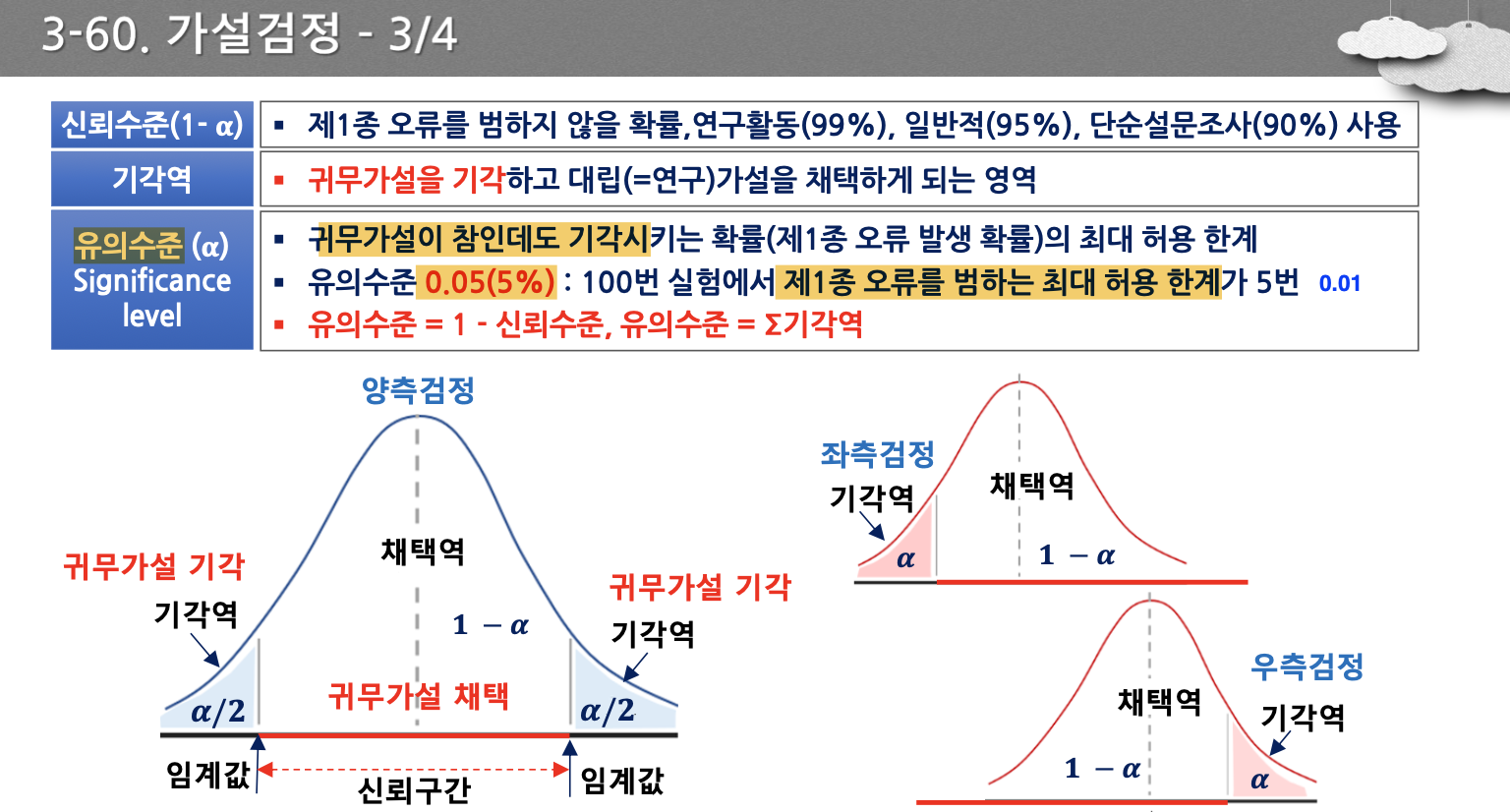
- 유의수준은 제 1종 오류의 최대 허용 한계이며, 일반적으로 0.05 정도를 사용한다. 문제에서 0.01인 경우도 있음
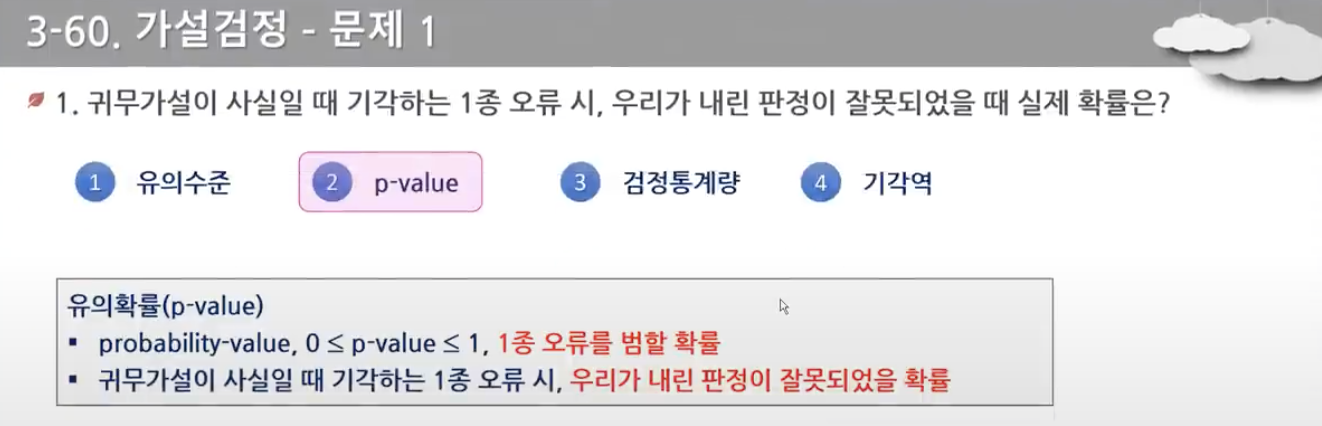
- 유의확률은 귀무가설이 사실일 때 기각하는 1종 오류 시 우리가 내린 판정이 잘못되었을 확률
- p-value가 0.05보다 작은 값을 갖게될 경우, 귀무가설을 기각하고 대립가설을 채택한다. 0.05보다 큰 값일 경우 귀무가설을 기각하지 못하고 채택한다.

- 귀무가설을 기각한다는 것은 p-value값이 α값보다 더 작은 경우이다.





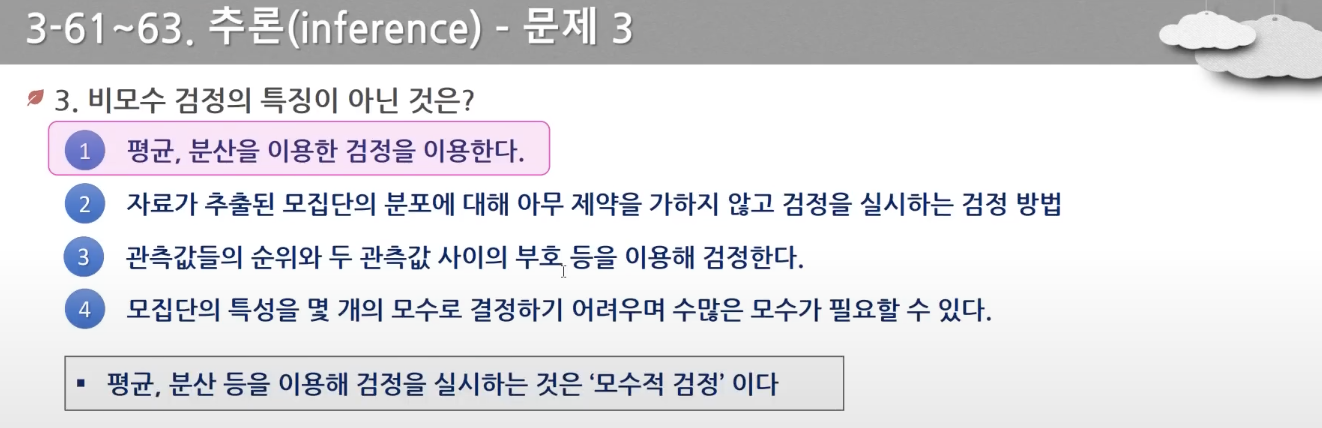
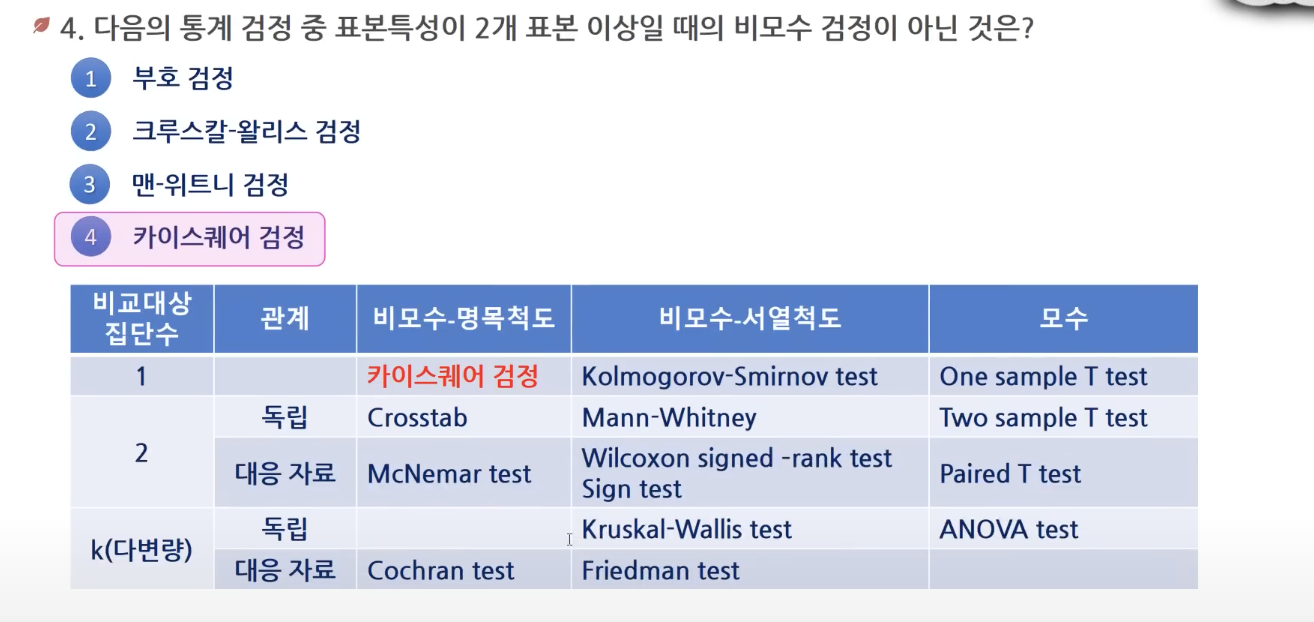
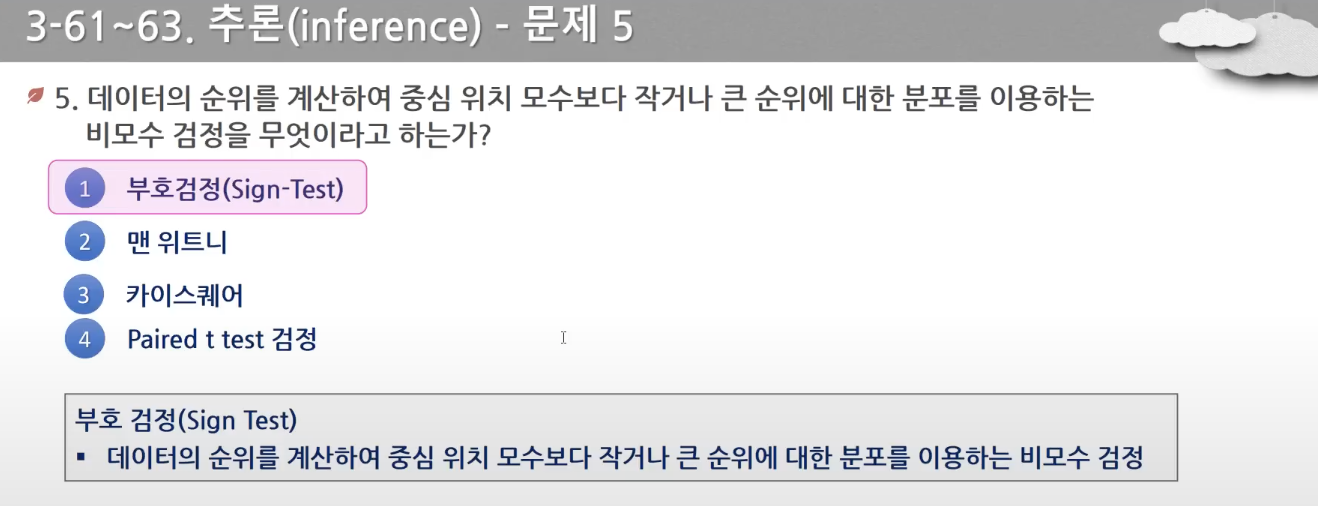
- 모수 자체인 평균, 분산보다는 분포의 형태에 관한 검정을 한다. 표본 수가 적고, 명목척도, 서열척도인 경우 사용한다.(성별, 혈액형, 만족도, 메달)
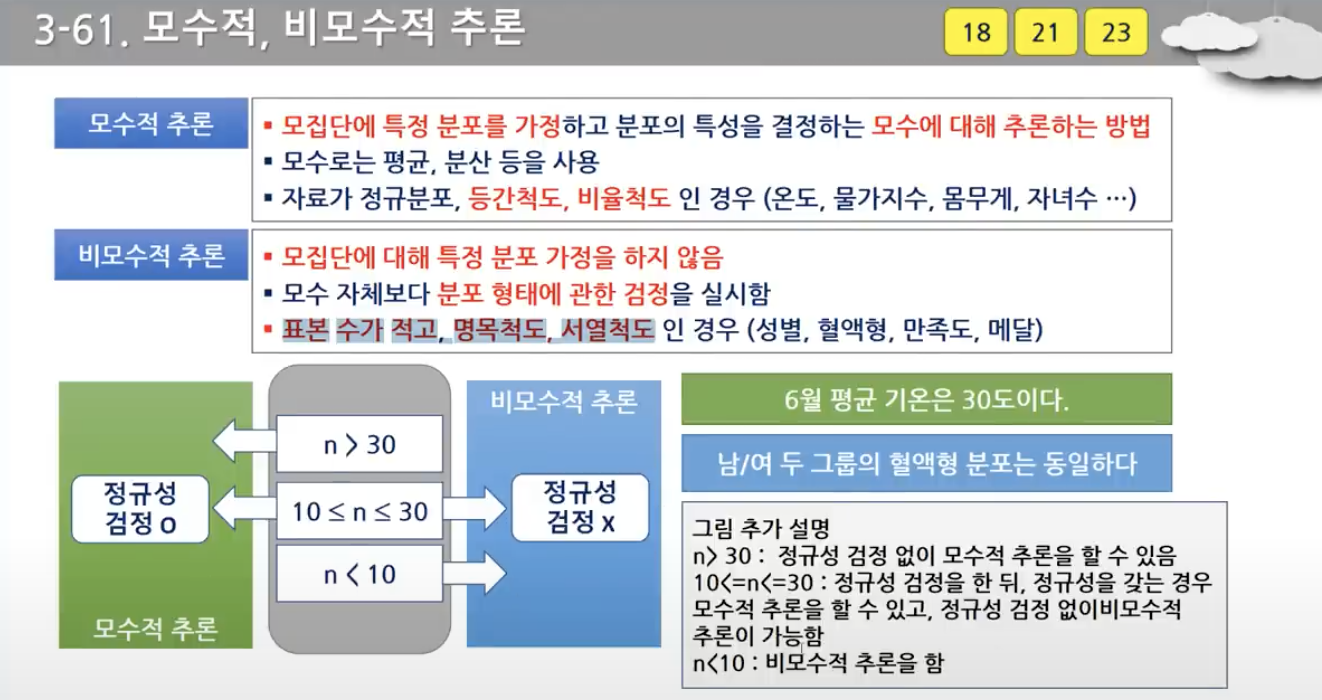

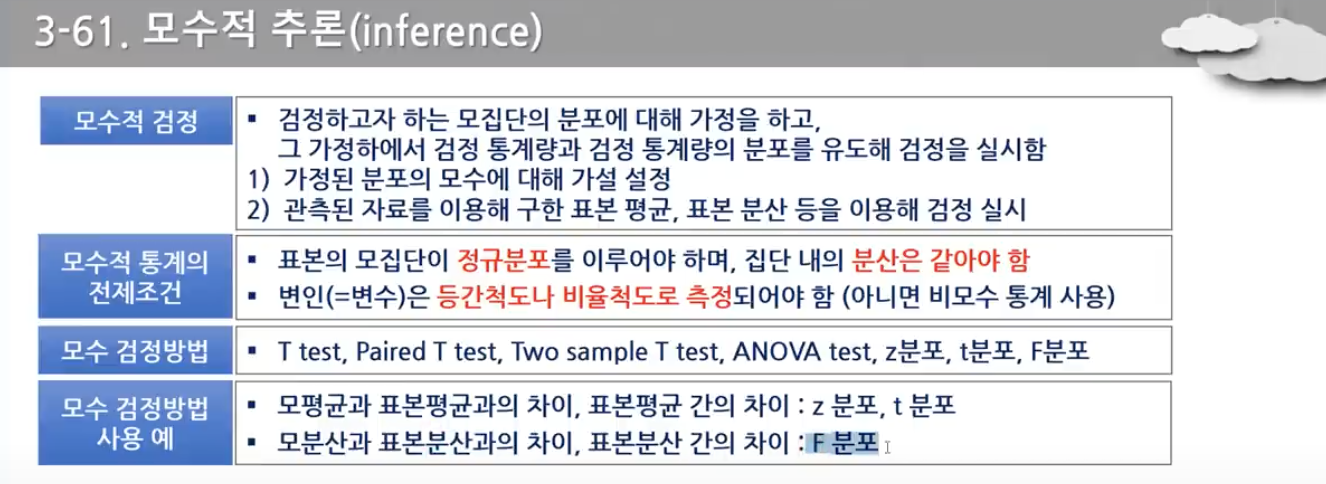


- T test는 평균에 관한 것이다.
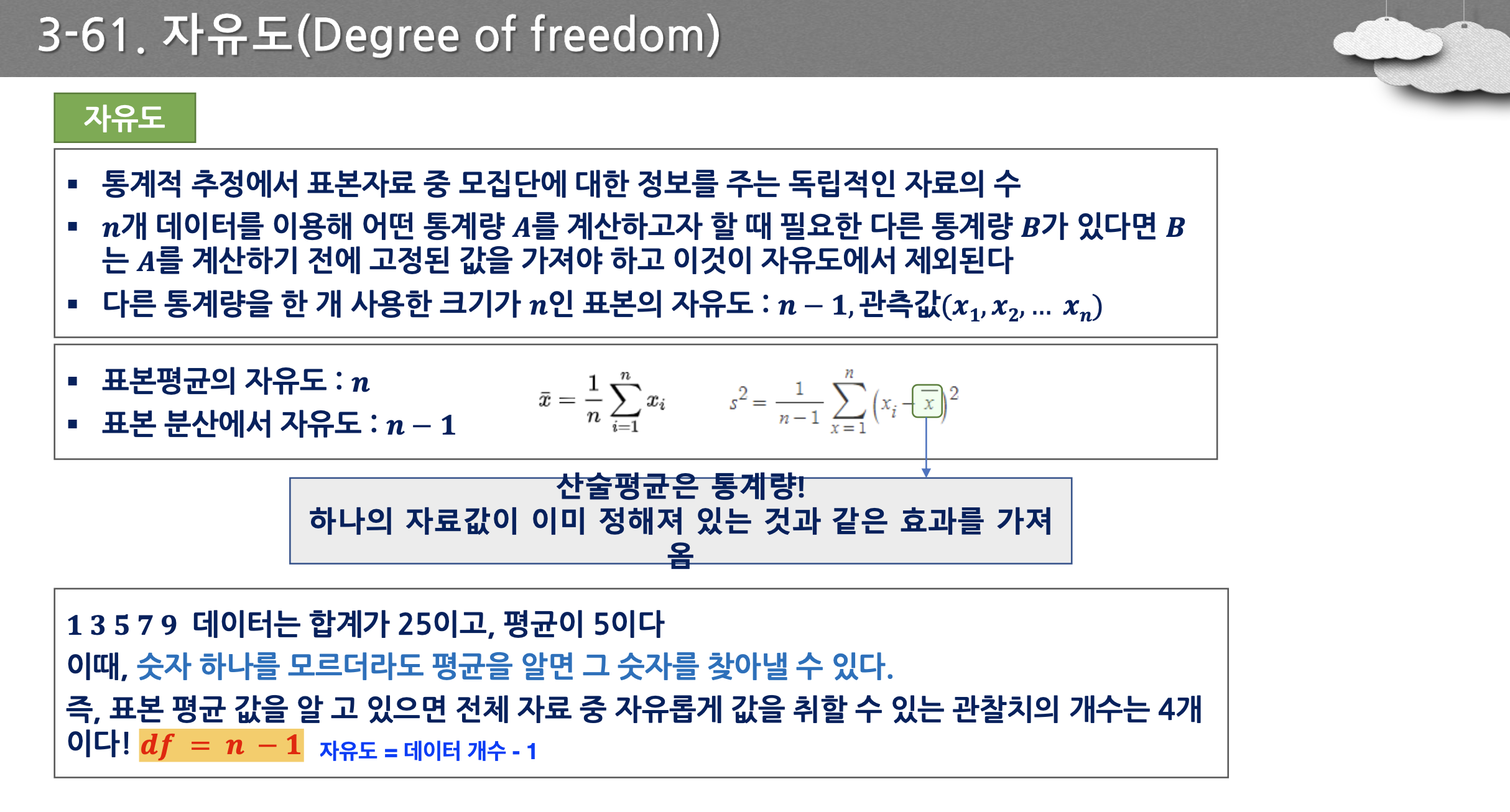
- 자유도는 데이터 갯수 - 1
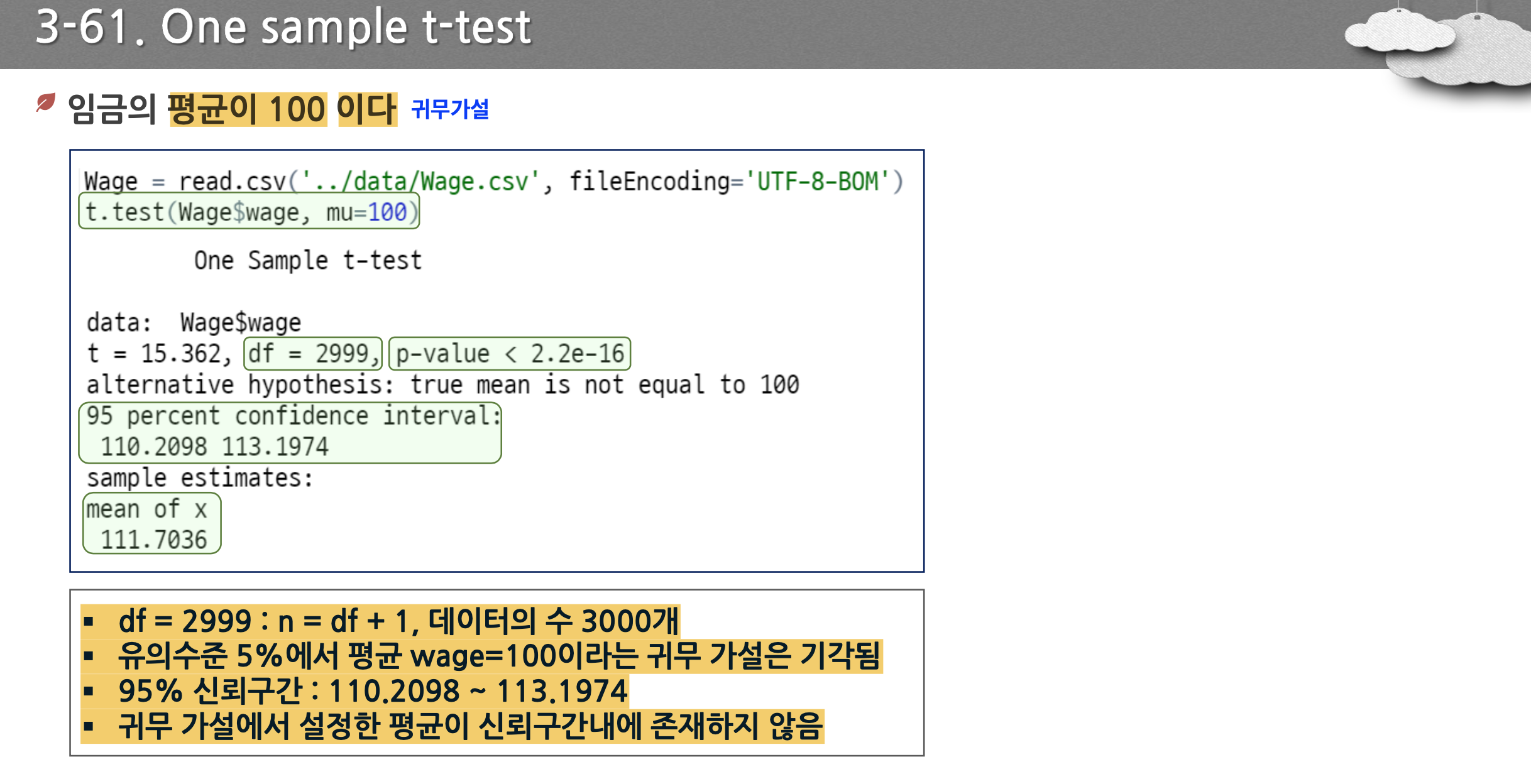
- t 테스트는 평균에 관한 것으로 mu=100과 같다는 귀무가설, 같지 않다가 대립가설

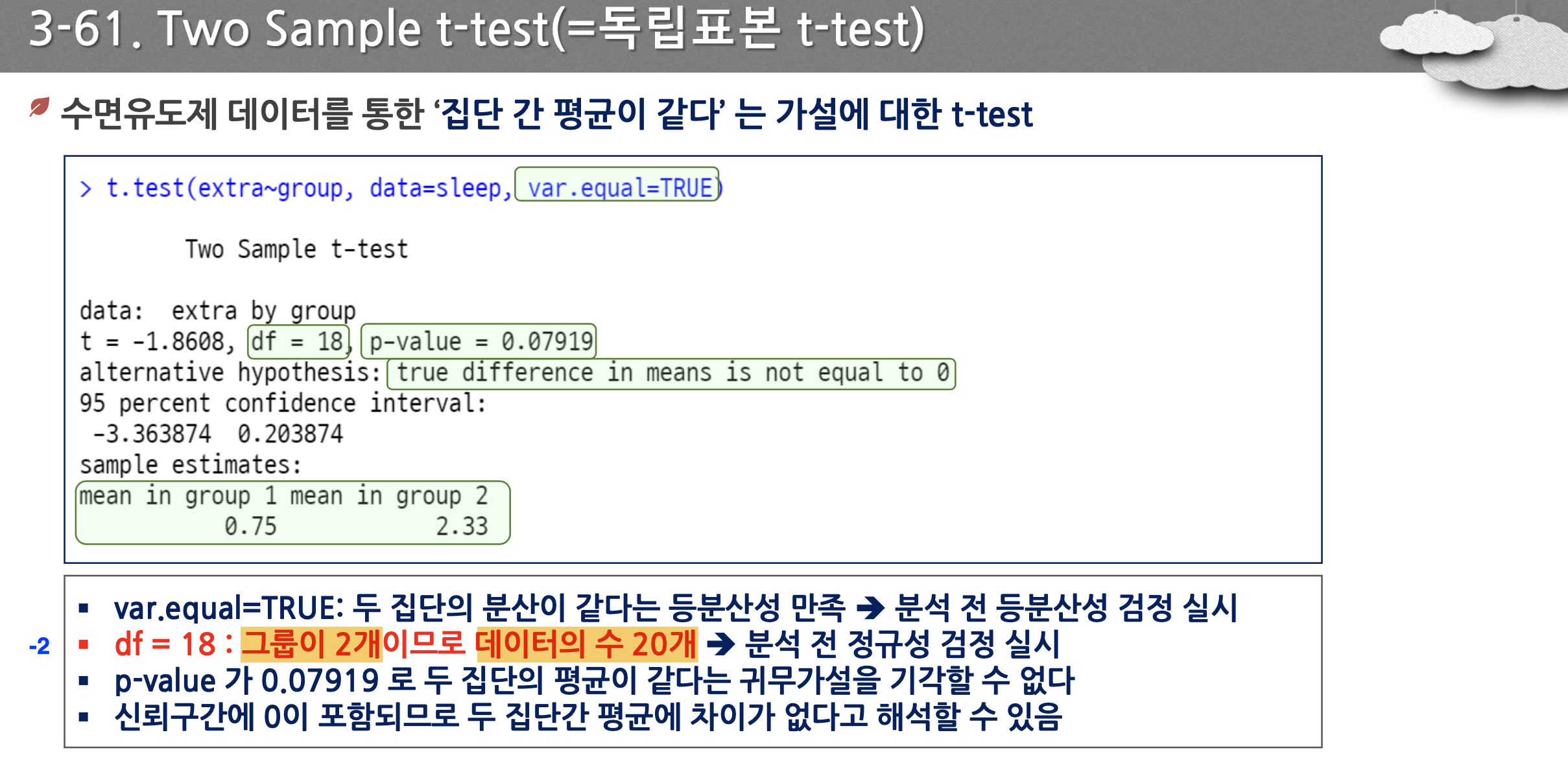
- 서로 다른 두 집단을 이용 → 그룹이 2개이므로 그룹의 갯수 2이므로 2를 뺀 것 ⇒ 데이터의 수 20개
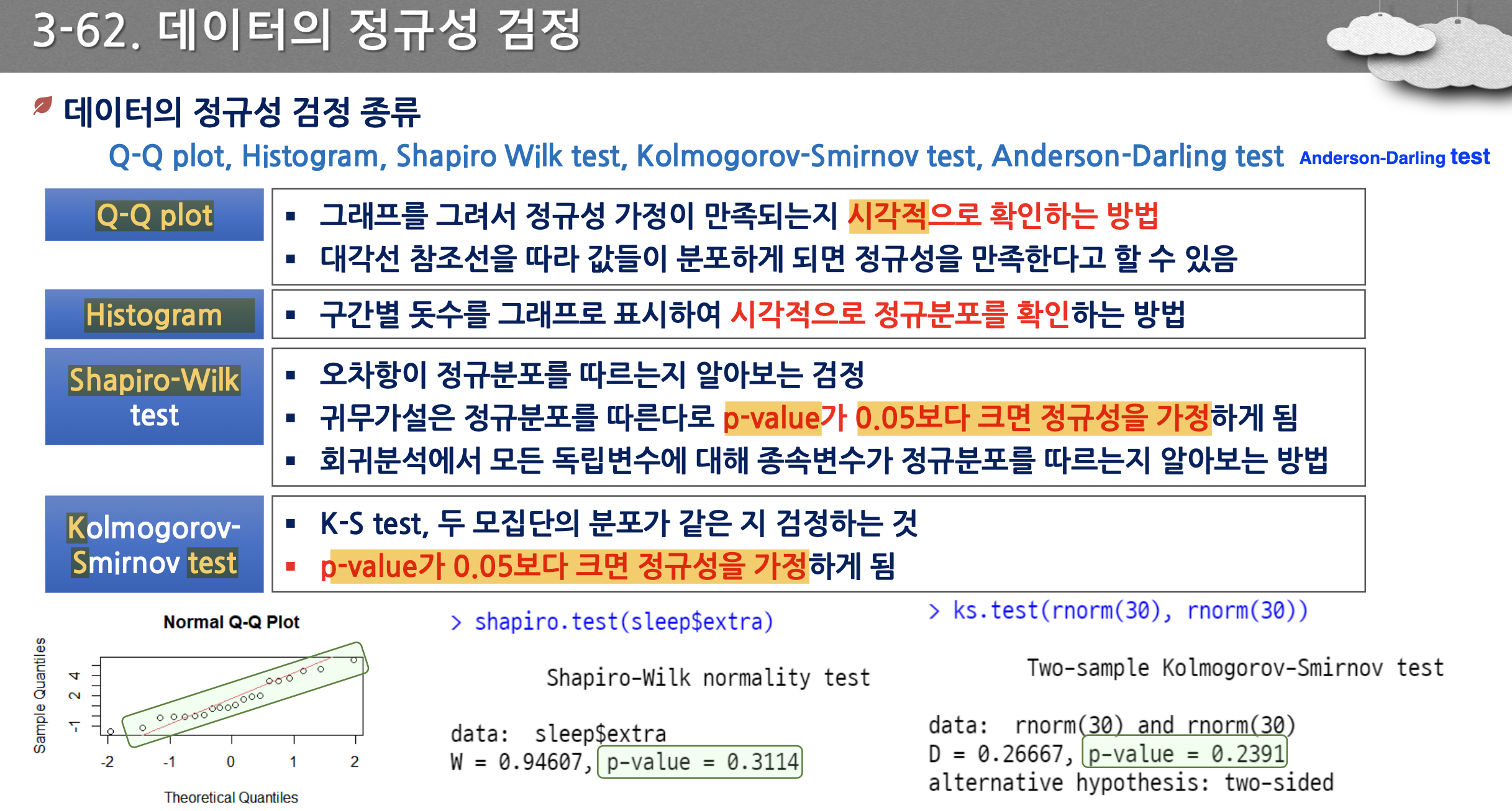
- 정규성 검정에 사용되는 것들

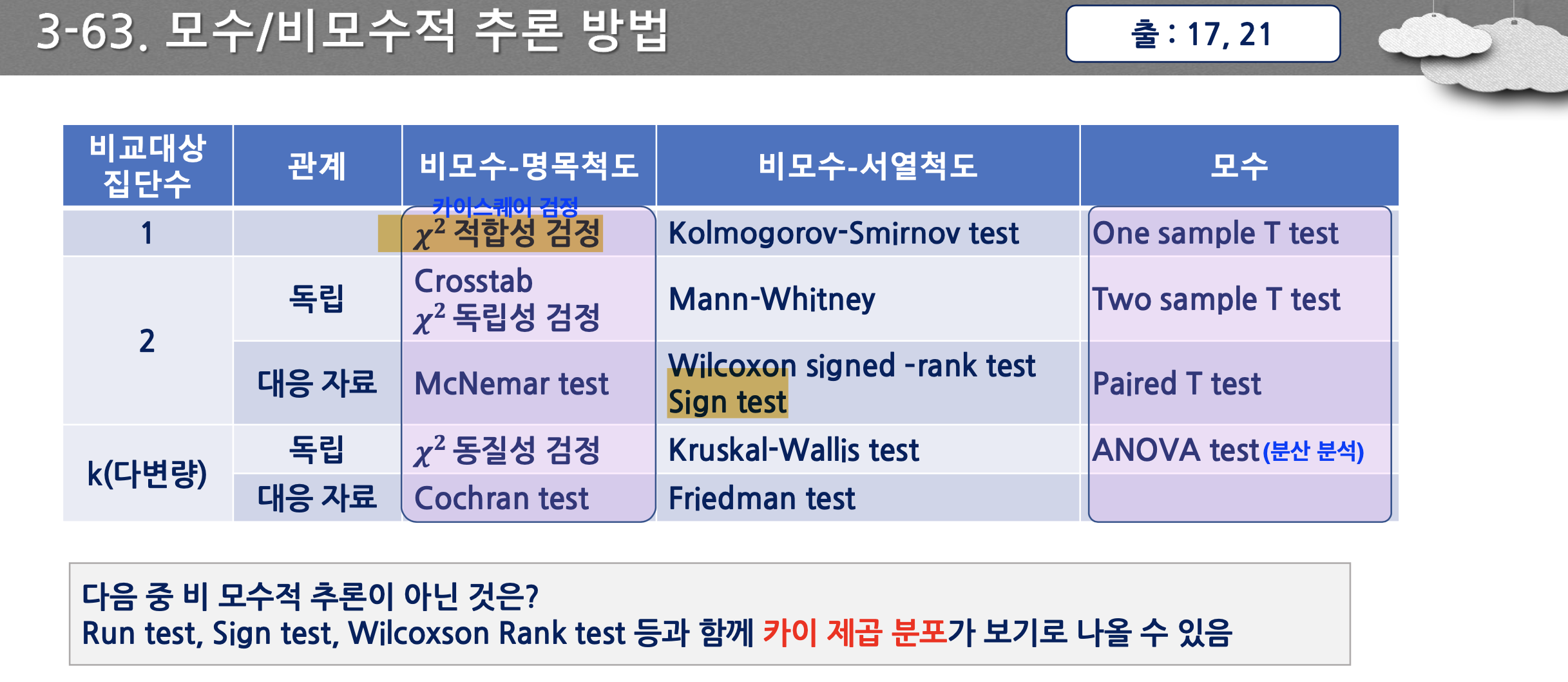


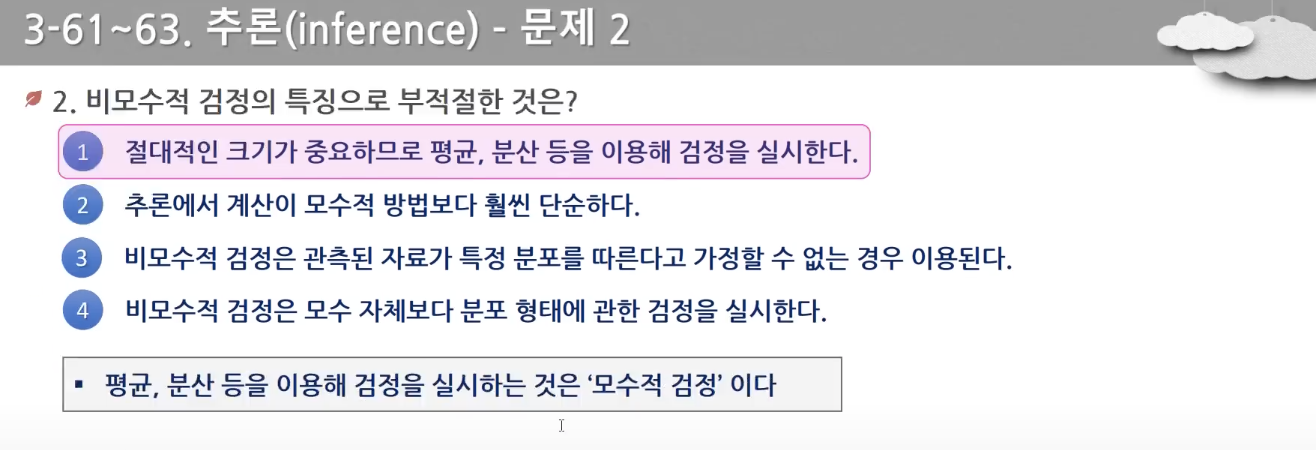


참고 자료
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.